Relationship-Embedded Representation Learning for Grounding Referring Expressions
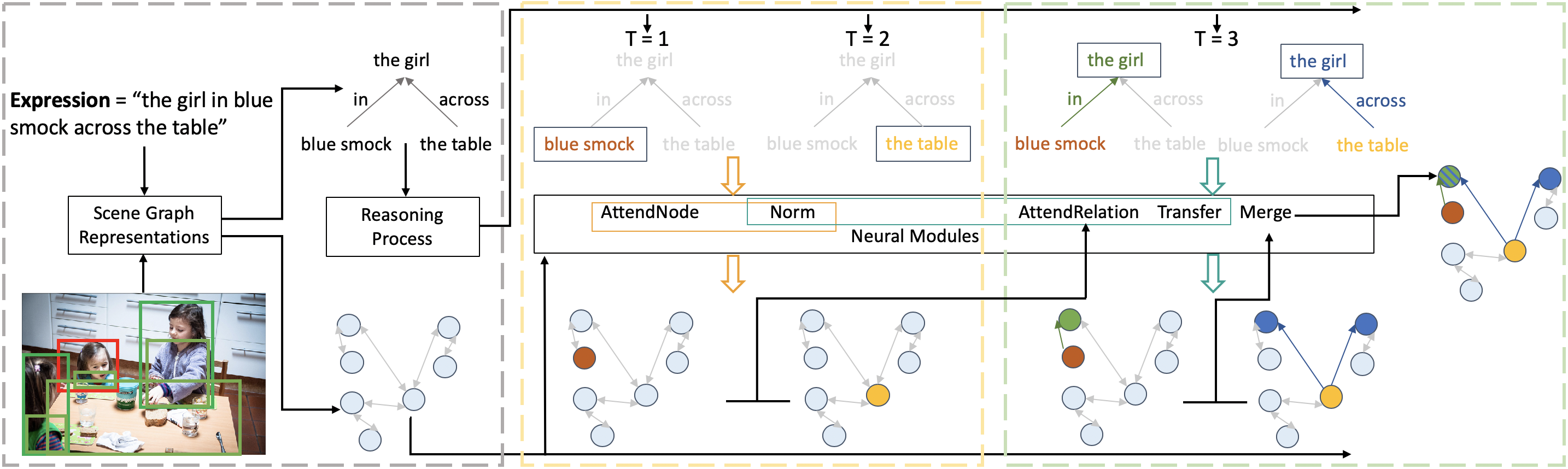
Grounding referring expressions in images aims to locate the object instance in an image described by a referring expression. It involves a joint understanding of natural language and image content, and is essential for a range of visual tasks related to human-computer interaction. As a language-to-vision matching task, the core of this problem is to not only extract all the necessary information (i.e., objects and the relationships among them) in both the image and referring expression, but also make full use of context information to align cross-modal semantic concepts in the extracted information. Unfortunately, existing work on grounding referring expressions fails to accurately extract multi-order relationships from the referring expression and associate them with the objects and their related contexts in the image. In this paper, we propose a Cross-Modal Relationship Extractor (CMRE) to adaptively highlight objects and relationships (spatial and semantic relations) related to the given expression with a cross-modal attention mechanism, and represent the extracted information as a language-guided visual relation graph. In addition, we propose a Gated Graph Convolutional Network (GGCN) to compute multimodal semantic contexts by fusing information from different modes and propagating multimodal information in the structured relation graph. Experimental results on three common benchmark datasets show that our Cross-Modal Relationship Inference Network, which consists of CMRE and GGCN, significantly surpasses all existing state-of-the-art methods. Code is available at https://github.com/sibeiyang/sgmn/tree/master/lib/cmrin_models
PDF Abstract


 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Visual Genome
Visual Genome
 RefCOCO
RefCOCO
