Cross-modality Data Augmentation for End-to-End Sign Language Translation
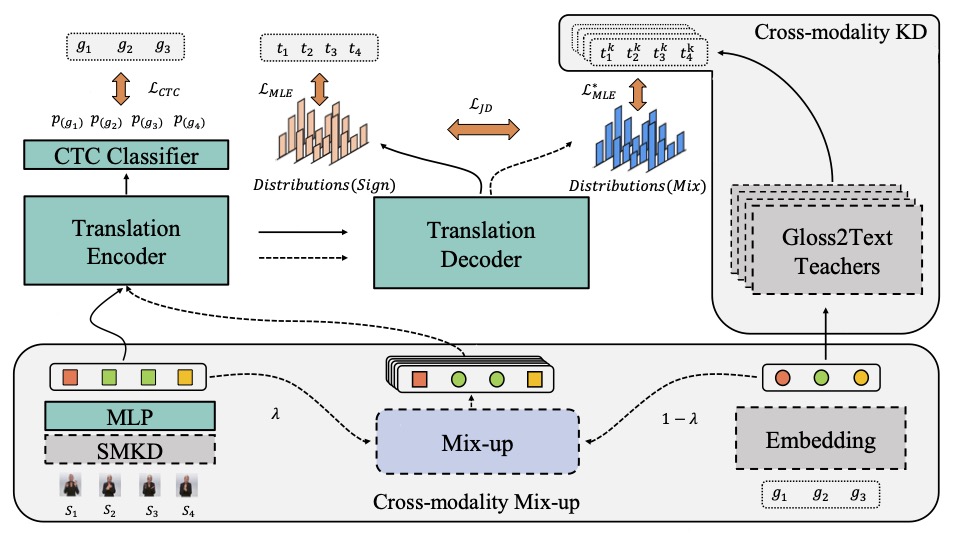
End-to-end sign language translation (SLT) aims to convert sign language videos into spoken language texts directly without intermediate representations. It has been a challenging task due to the modality gap between sign videos and texts and the data scarcity of labeled data. To tackle these challenges, we propose a novel Cross-modality Data Augmentation (XmDA) framework to transfer the powerful gloss-to-text translation capabilities to end-to-end sign language translation (i.e. video-to-text) by exploiting pseudo gloss-text pairs from the sign gloss translation model. Specifically, XmDA consists of two key components, namely, cross-modality mix-up and cross-modality knowledge distillation. The former explicitly encourages the alignment between sign video features and gloss embeddings to bridge the modality gap. The latter utilizes the generation knowledge from gloss-to-text teacher models to guide the spoken language text generation. Experimental results on two widely used SLT datasets, i.e., PHOENIX-2014T and CSL-Daily, demonstrate that the proposed XmDA framework significantly and consistently outperforms the baseline models. Extensive analyses confirm our claim that XmDA enhances spoken language text generation by reducing the representation distance between videos and texts, as well as improving the processing of low-frequency words and long sentences.
PDF Abstract




