DADA: Deep Adversarial Data Augmentation for Extremely Low Data Regime Classification
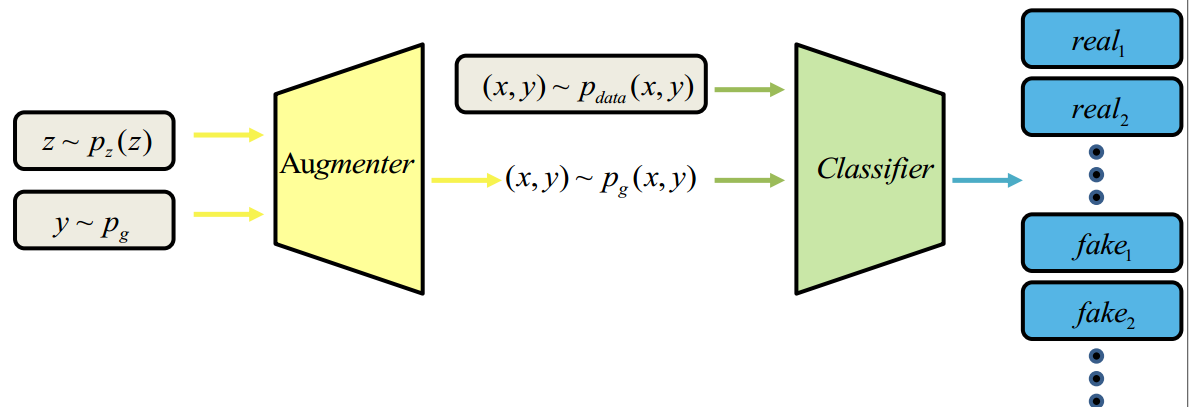
Deep learning has revolutionized the performance of classification, but meanwhile demands sufficient labeled data for training. Given insufficient data, while many techniques have been developed to help combat overfitting, the challenge remains if one tries to train deep networks, especially in the ill-posed extremely low data regimes: only a small set of labeled data are available, and nothing -- including unlabeled data -- else. Such regimes arise from practical situations where not only data labeling but also data collection itself is expensive. We propose a deep adversarial data augmentation (DADA) technique to address the problem, in which we elaborately formulate data augmentation as a problem of training a class-conditional and supervised generative adversarial network (GAN). Specifically, a new discriminator loss is proposed to fit the goal of data augmentation, through which both real and augmented samples are enforced to contribute to and be consistent in finding the decision boundaries. Tailored training techniques are developed accordingly. To quantitatively validate its effectiveness, we first perform extensive simulations to show that DADA substantially outperforms both traditional data augmentation and a few GAN-based options. We then extend experiments to three real-world small labeled datasets where existing data augmentation and/or transfer learning strategies are either less effective or infeasible. All results endorse the superior capability of DADA in enhancing the generalization ability of deep networks trained in practical extremely low data regimes. Source code is available at https://github.com/SchafferZhang/DADA.
PDF Abstract




