Label-Assemble: Leveraging Multiple Datasets with Partial Labels
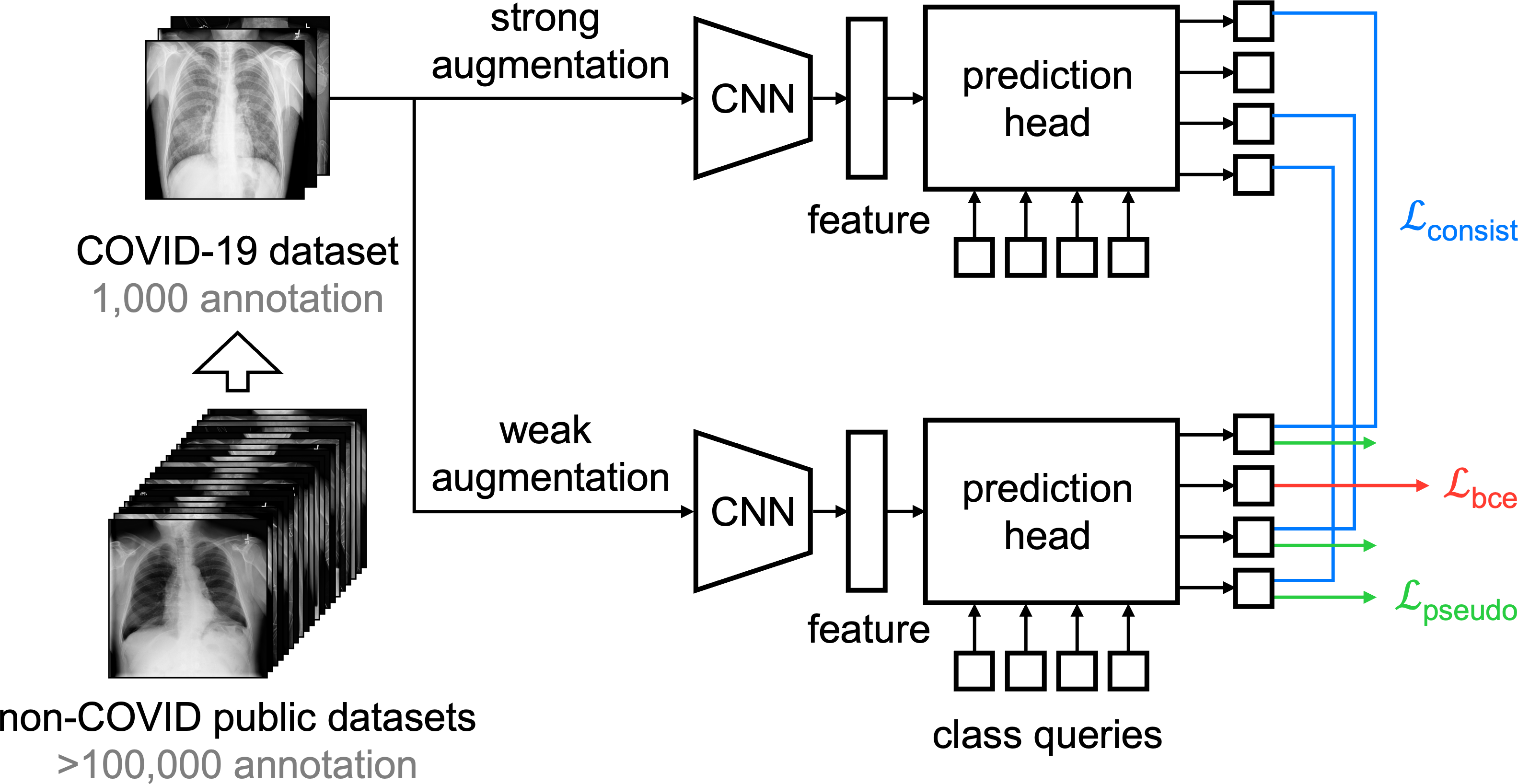
The success of deep learning relies heavily on large labeled datasets, but we often only have access to several small datasets associated with partial labels. To address this problem, we propose a new initiative, "Label-Assemble", that aims to unleash the full potential of partial labels from an assembly of public datasets. We discovered that learning from negative examples facilitates both computer-aided disease diagnosis and detection. This discovery will be particularly crucial in novel disease diagnosis, where positive examples are hard to collect, yet negative examples are relatively easier to assemble. For example, assembling existing labels from NIH ChestX-ray14 (available since 2017) significantly improves the accuracy of COVID-19 diagnosis from 96.3% to 99.3%. In addition to diagnosis, assembling labels can also improve disease detection, e.g., the detection of pancreatic ductal adenocarcinoma (PDAC) can greatly benefit from leveraging the labels of Cysts and PanNets (two other types of pancreatic abnormalities), increasing sensitivity from 52.1% to 84.0% while maintaining a high specificity of 98.0%.
PDF Abstract


 CheXpert
CheXpert
 ChestX-ray14
ChestX-ray14
