Data-efficient Large Vision Models through Sequential Autoregression
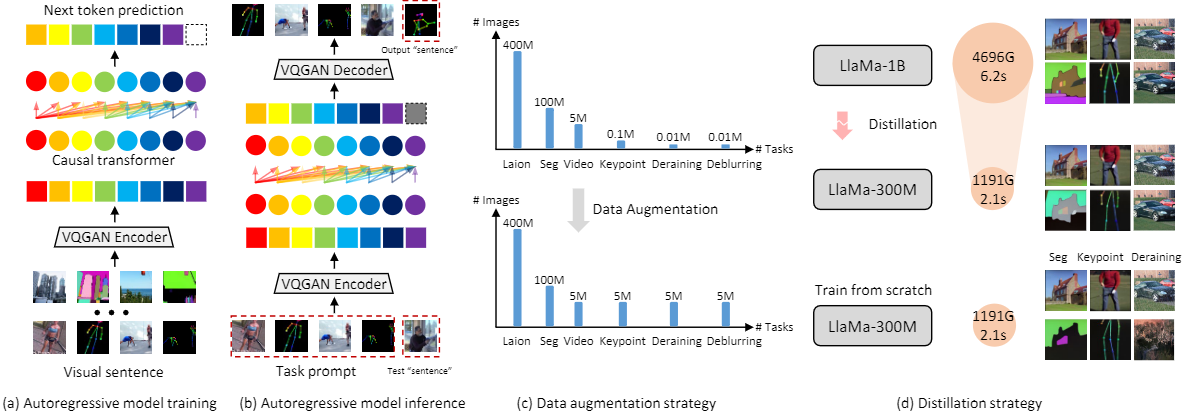
Training general-purpose vision models on purely sequential visual data, eschewing linguistic inputs, has heralded a new frontier in visual understanding. These models are intended to not only comprehend but also seamlessly transit to out-of-domain tasks. However, current endeavors are hamstrung by an over-reliance on colossal models, exemplified by models with upwards of 3B parameters, and the necessity for an extensive corpus of visual data, often comprising a staggering 400B tokens. In this paper, we delve into the development of an efficient, autoregression-based vision model, innovatively architected to operate on a limited dataset. We meticulously demonstrate how this model achieves proficiency in a spectrum of visual tasks spanning both high-level and low-level semantic understanding during the testing phase. Our empirical evaluations underscore the model's agility in adapting to various tasks, heralding a significant reduction in the parameter footprint, and a marked decrease in training data requirements, thereby paving the way for more sustainable and accessible advancements in the field of generalist vision models. The code is available at https://github.com/ggjy/DeLVM.
PDF Abstract
 MS COCO
MS COCO
 SA-1B
SA-1B
