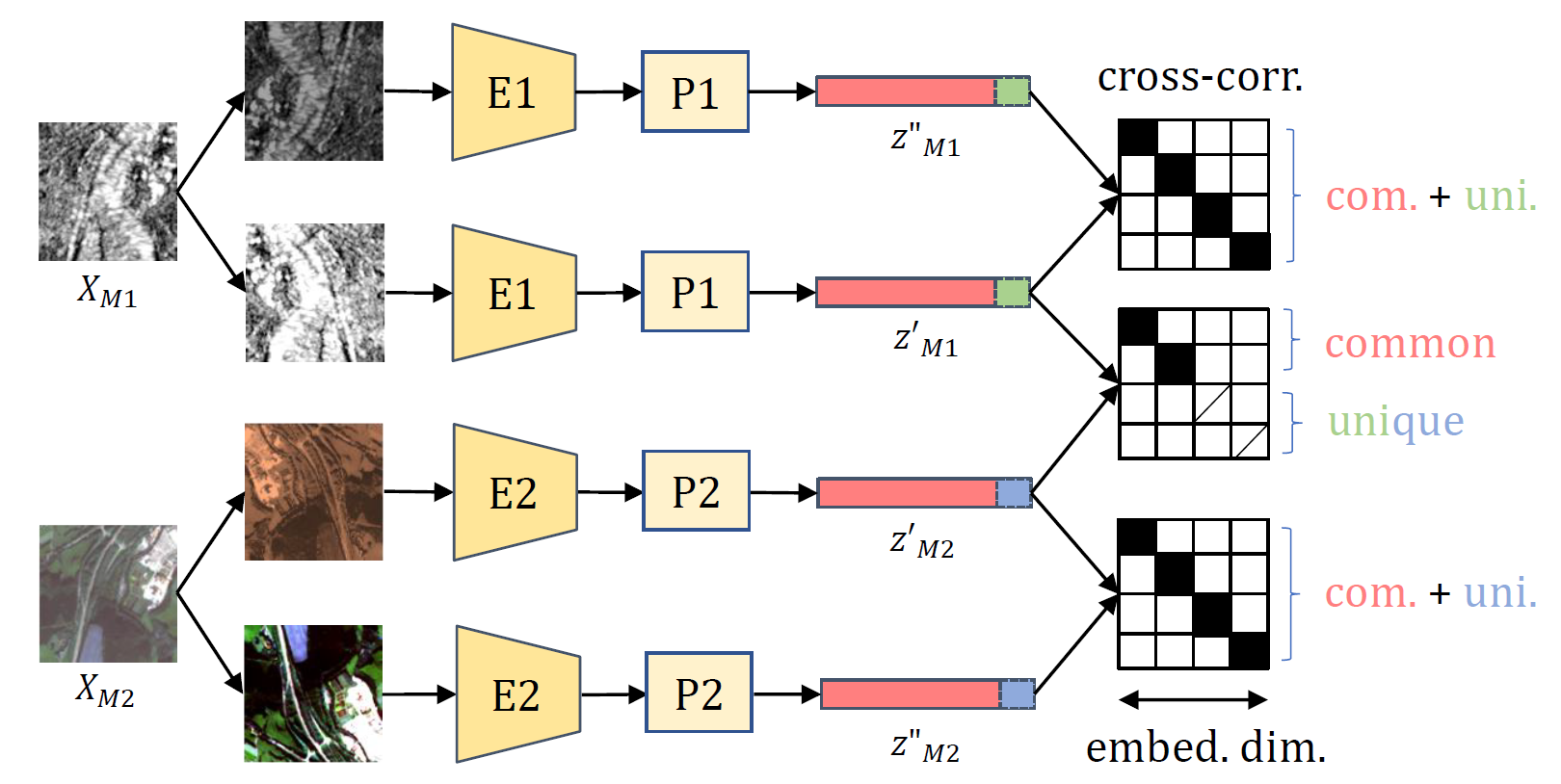
DeCUR: decoupling common & unique representations for multimodal self-supervision
The increasing availability of multi-sensor data sparks interest in multimodal self-supervised learning. However, most existing approaches learn only common representations across modalities while ignoring intra-modal training and modality-unique representations. We propose Decoupling Common and Unique Representations (DeCUR), a simple yet effective method for multimodal self-supervised learning. By distinguishing inter- and intra-modal embeddings, DeCUR is trained to integrate complementary information across different modalities. We evaluate DeCUR in three common multimodal scenarios (radar-optical, RGB-elevation, and RGB-depth), and demonstrate its consistent benefits on scene classification and semantic segmentation downstream tasks. Notably, we get straightforward improvements by transferring our pretrained backbones to state-of-the-art supervised multimodal methods without any hyperparameter tuning. Furthermore, we conduct a comprehensive explainability analysis to shed light on the interpretation of common and unique features in our multimodal approach. Codes are available at \url{https://github.com/zhu-xlab/DeCUR}.
PDF Abstract



 NYUv2
NYUv2
 SUN RGB-D
SUN RGB-D
 SSL4EO-S12
SSL4EO-S12
