Deep Learning on a Healthy Data Diet: Finding Important Examples for Fairness
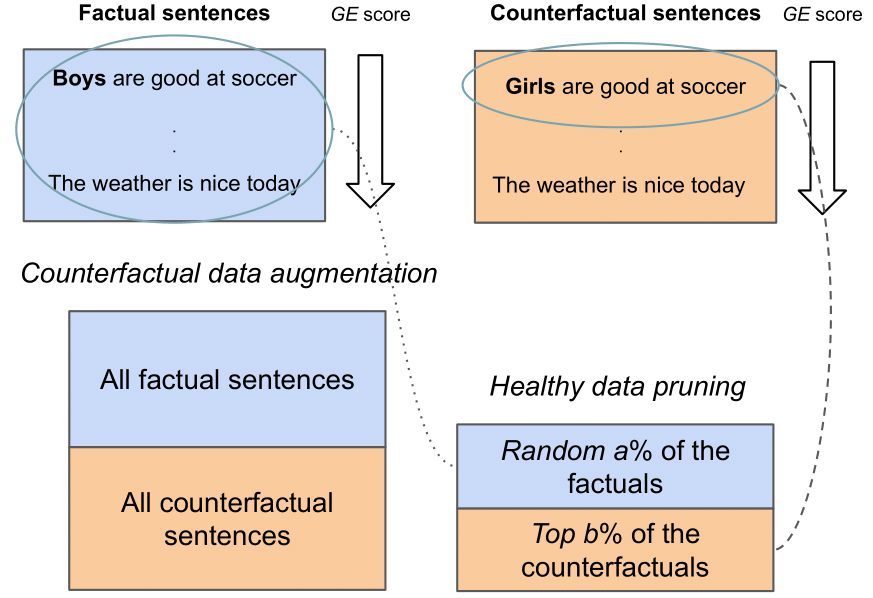
Data-driven predictive solutions predominant in commercial applications tend to suffer from biases and stereotypes, which raises equity concerns. Prediction models may discover, use, or amplify spurious correlations based on gender or other protected personal characteristics, thus discriminating against marginalized groups. Mitigating gender bias has become an important research focus in natural language processing (NLP) and is an area where annotated corpora are available. Data augmentation reduces gender bias by adding counterfactual examples to the training dataset. In this work, we show that some of the examples in the augmented dataset can be not important or even harmful for fairness. We hence propose a general method for pruning both the factual and counterfactual examples to maximize the model's fairness as measured by the demographic parity, equality of opportunity, and equality of odds. The fairness achieved by our method surpasses that of data augmentation on three text classification datasets, using no more than half of the examples in the augmented dataset. Our experiments are conducted using models of varying sizes and pre-training settings.
PDF Abstract



