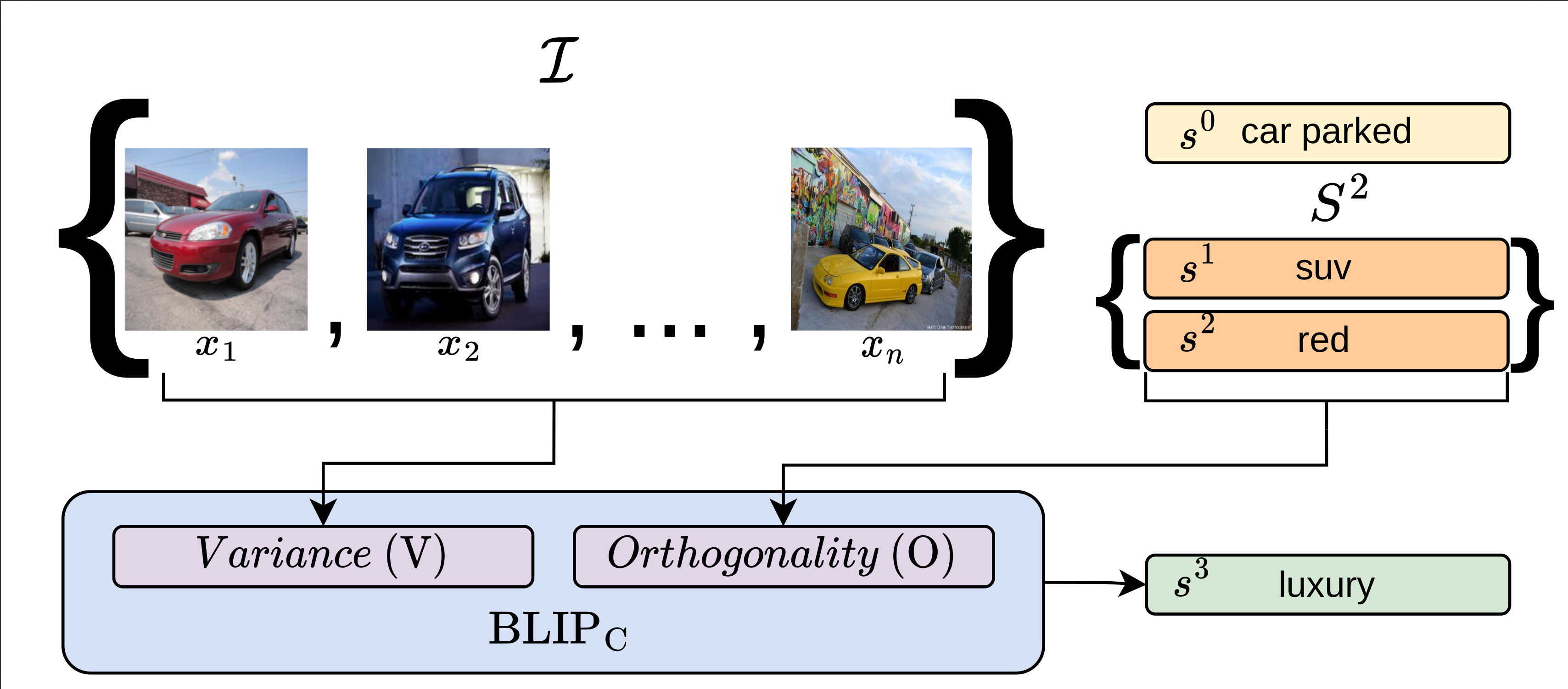
Describing Sets of Images with Textual-PCA
We seek to semantically describe a set of images, capturing both the attributes of single images and the variations within the set. Our procedure is analogous to Principle Component Analysis, in which the role of projection vectors is replaced with generated phrases. First, a centroid phrase that has the largest average semantic similarity to the images in the set is generated, where both the computation of the similarity and the generation are based on pretrained vision-language models. Then, the phrase that generates the highest variation among the similarity scores is generated, using the same models. The next phrase maximizes the variance subject to being orthogonal, in the latent space, to the highest-variance phrase, and the process continues. Our experiments show that our method is able to convincingly capture the essence of image sets and describe the individual elements in a semantically meaningful way within the context of the entire set. Our code is available at: https://github.com/OdedH/textual-pca.
PDF Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
 LSUN
LSUN
