DiffuseVAE: Efficient, Controllable and High-Fidelity Generation from Low-Dimensional Latents
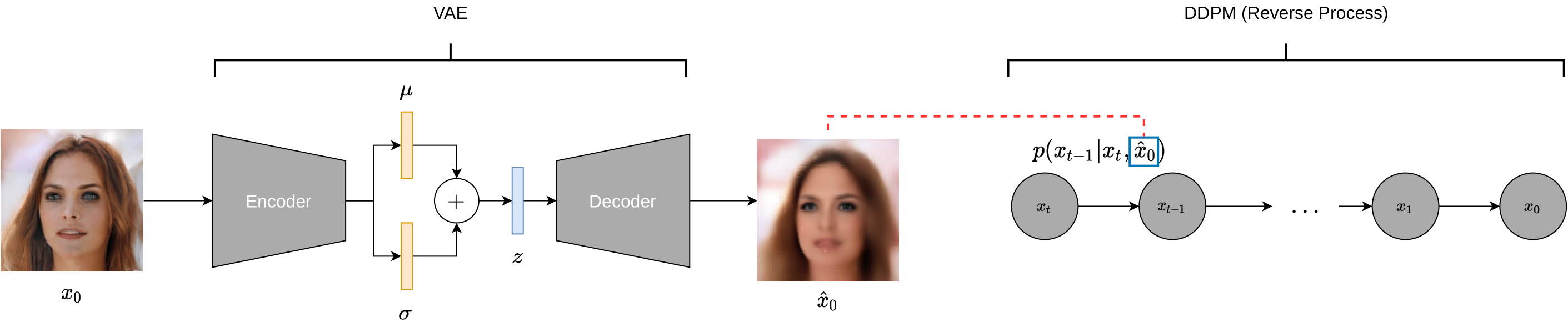
Diffusion probabilistic models have been shown to generate state-of-the-art results on several competitive image synthesis benchmarks but lack a low-dimensional, interpretable latent space, and are slow at generation. On the other hand, standard Variational Autoencoders (VAEs) typically have access to a low-dimensional latent space but exhibit poor sample quality. We present DiffuseVAE, a novel generative framework that integrates VAE within a diffusion model framework, and leverage this to design novel conditional parameterizations for diffusion models. We show that the resulting model equips diffusion models with a low-dimensional VAE inferred latent code which can be used for downstream tasks like controllable synthesis. The proposed method also improves upon the speed vs quality tradeoff exhibited in standard unconditional DDPM/DDIM models (for instance, FID of 16.47 vs 34.36 using a standard DDIM on the CelebA-HQ-128 benchmark using T=10 reverse process steps) without having explicitly trained for such an objective. Furthermore, the proposed model exhibits synthesis quality comparable to state-of-the-art models on standard image synthesis benchmarks like CIFAR-10 and CelebA-64 while outperforming most existing VAE-based methods. Lastly, we show that the proposed method exhibits inherent generalization to different types of noise in the conditioning signal. For reproducibility, our source code is publicly available at https://github.com/kpandey008/DiffuseVAE.
PDF Abstract


 CIFAR-10
CIFAR-10
 CelebA
CelebA
 CelebA-HQ
CelebA-HQ

