Discrete Probabilistic Inference as Control in Multi-path Environments
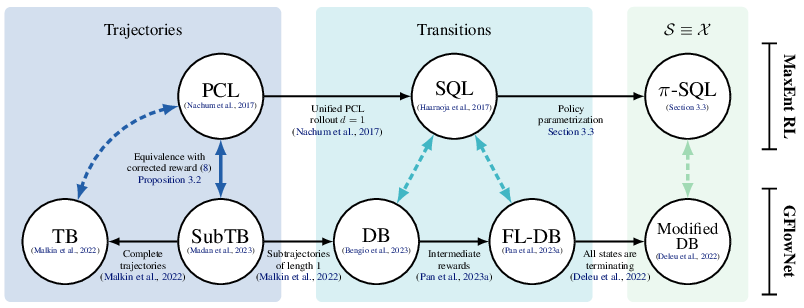
We consider the problem of sampling from a discrete and structured distribution as a sequential decision problem, where the objective is to find a stochastic policy such that objects are sampled at the end of this sequential process proportionally to some predefined reward. While we could use maximum entropy Reinforcement Learning (MaxEnt RL) to solve this problem for some distributions, it has been shown that in general, the distribution over states induced by the optimal policy may be biased in cases where there are multiple ways to generate the same object. To address this issue, Generative Flow Networks (GFlowNets) learn a stochastic policy that samples objects proportionally to their reward by approximately enforcing a conservation of flows across the whole Markov Decision Process (MDP). In this paper, we extend recent methods correcting the reward in order to guarantee that the marginal distribution induced by the optimal MaxEnt RL policy is proportional to the original reward, regardless of the structure of the underlying MDP. We also prove that some flow-matching objectives found in the GFlowNet literature are in fact equivalent to well-established MaxEnt RL algorithms with a corrected reward. Finally, we study empirically the performance of multiple MaxEnt RL and GFlowNet algorithms on multiple problems involving sampling from discrete distributions.
PDF Abstract
