DVIS: Decoupled Video Instance Segmentation Framework
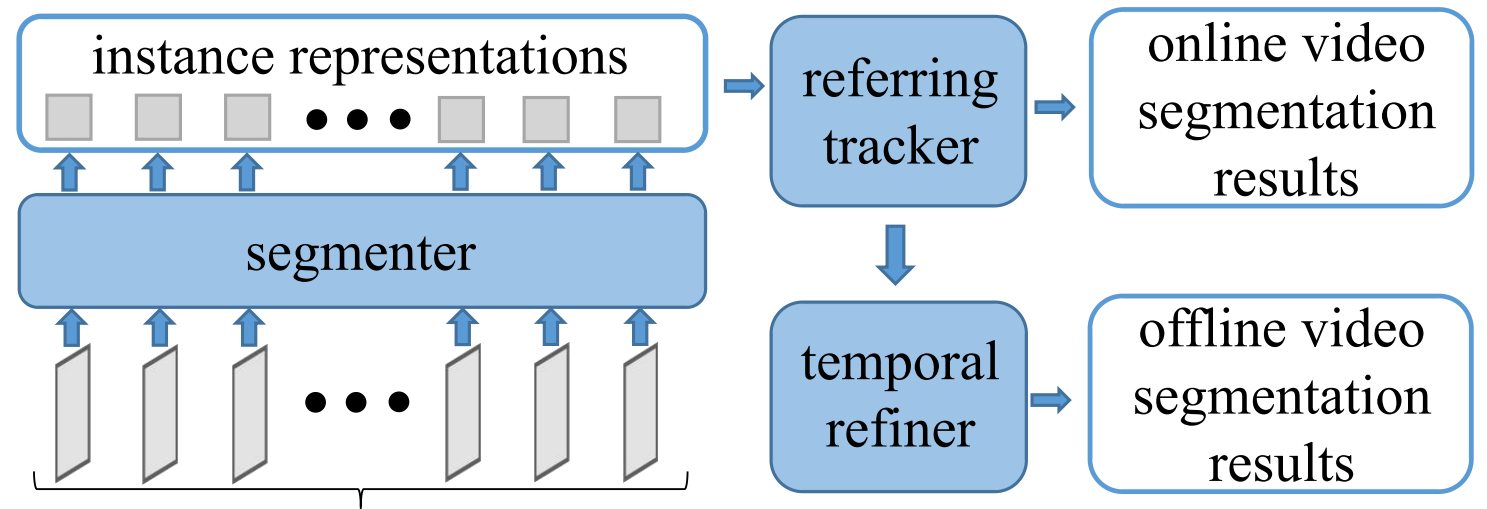
Video instance segmentation (VIS) is a critical task with diverse applications, including autonomous driving and video editing. Existing methods often underperform on complex and long videos in real world, primarily due to two factors. Firstly, offline methods are limited by the tightly-coupled modeling paradigm, which treats all frames equally and disregards the interdependencies between adjacent frames. Consequently, this leads to the introduction of excessive noise during long-term temporal alignment. Secondly, online methods suffer from inadequate utilization of temporal information. To tackle these challenges, we propose a decoupling strategy for VIS by dividing it into three independent sub-tasks: segmentation, tracking, and refinement. The efficacy of the decoupling strategy relies on two crucial elements: 1) attaining precise long-term alignment outcomes via frame-by-frame association during tracking, and 2) the effective utilization of temporal information predicated on the aforementioned accurate alignment outcomes during refinement. We introduce a novel referring tracker and temporal refiner to construct the \textbf{D}ecoupled \textbf{VIS} framework (\textbf{DVIS}). DVIS achieves new SOTA performance in both VIS and VPS, surpassing the current SOTA methods by 7.3 AP and 9.6 VPQ on the OVIS and VIPSeg datasets, which are the most challenging and realistic benchmarks. Moreover, thanks to the decoupling strategy, the referring tracker and temporal refiner are super light-weight (only 1.69\% of the segmenter FLOPs), allowing for efficient training and inference on a single GPU with 11G memory. The code is available at \href{https://github.com/zhang-tao-whu/DVIS}{https://github.com/zhang-tao-whu/DVIS}.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract





 YouTube-VIS 2019
YouTube-VIS 2019
 OVIS
OVIS
 Youtube-VIS 2022 Validation
Youtube-VIS 2022 Validation

