Dynamic Multimodal Fusion
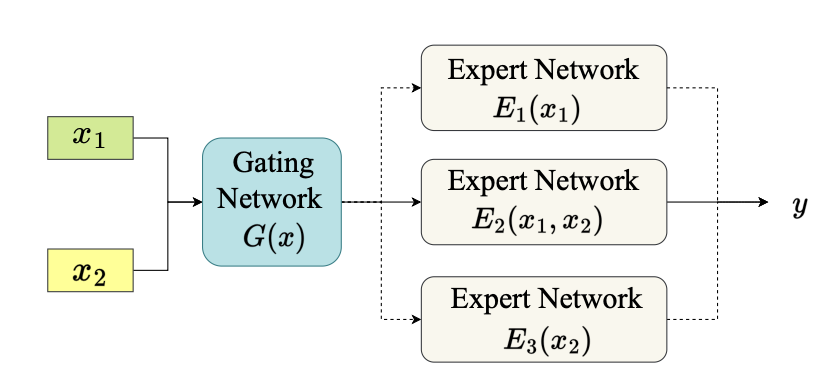
Deep multimodal learning has achieved great progress in recent years. However, current fusion approaches are static in nature, i.e., they process and fuse multimodal inputs with identical computation, without accounting for diverse computational demands of different multimodal data. In this work, we propose dynamic multimodal fusion (DynMM), a new approach that adaptively fuses multimodal data and generates data-dependent forward paths during inference. To this end, we propose a gating function to provide modality-level or fusion-level decisions on-the-fly based on multimodal features and a resource-aware loss function that encourages computational efficiency. Results on various multimodal tasks demonstrate the efficiency and wide applicability of our approach. For instance, DynMM can reduce the computation costs by 46.5% with only a negligible accuracy loss (CMU-MOSEI sentiment analysis) and improve segmentation performance with over 21% savings in computation (NYU Depth V2 semantic segmentation) when compared with static fusion approaches. We believe our approach opens a new direction towards dynamic multimodal network design, with applications to a wide range of multimodal tasks.
PDF Abstract



 NYUv2
NYUv2
 CMU-MOSEI
CMU-MOSEI

