Efficiently Programming Large Language Models using SGLang
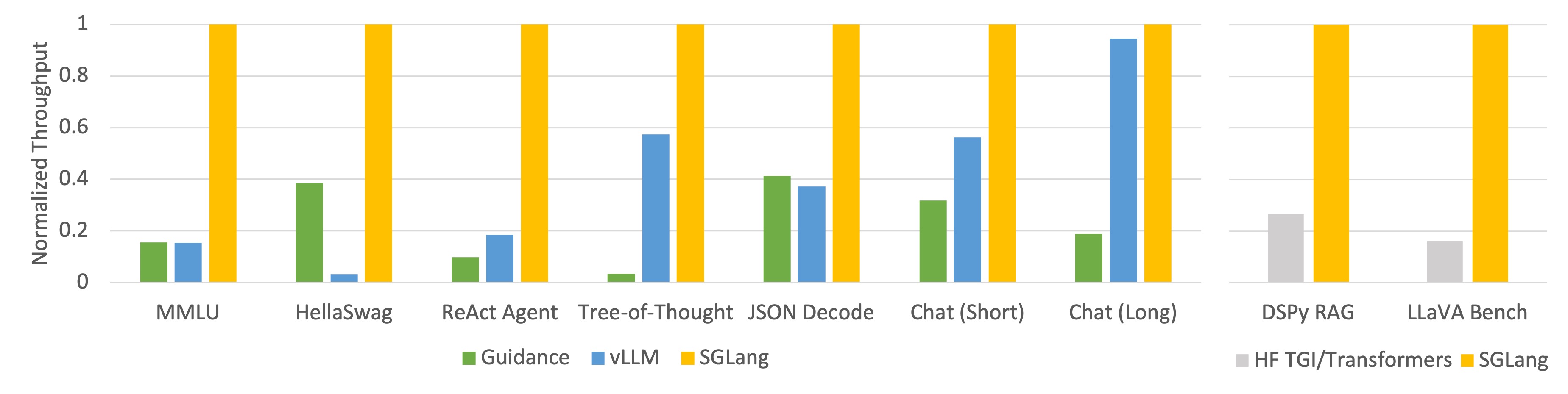
Large language models (LLMs) are increasingly used for complex tasks requiring multiple chained generation calls, advanced prompting techniques, control flow, and interaction with external environments. However, efficient systems for programming and executing these applications are lacking. To bridge this gap, we introduce SGLang, a Structured Generation Language for LLMs. SGLang is designed for the efficient programming of LLMs and incorporates primitives for common LLM programming patterns. We have implemented SGLang as a domain-specific language embedded in Python, and we developed an interpreter, a compiler, and a high-performance runtime for SGLang. These components work together to enable optimizations such as parallelism, batching, caching, sharing, and other compilation techniques. Additionally, we propose RadixAttention, a novel technique that maintains a Least Recently Used (LRU) cache of the Key-Value (KV) cache for all requests in a radix tree, enabling automatic KV cache reuse across multiple generation calls at runtime. SGLang simplifies the writing of LLM programs and boosts execution efficiency. Our experiments demonstrate that SGLang can speed up common LLM tasks by up to 5x, while reducing code complexity and enhancing control.
PDF Abstract MMLU
MMLU
 HellaSwag
HellaSwag
