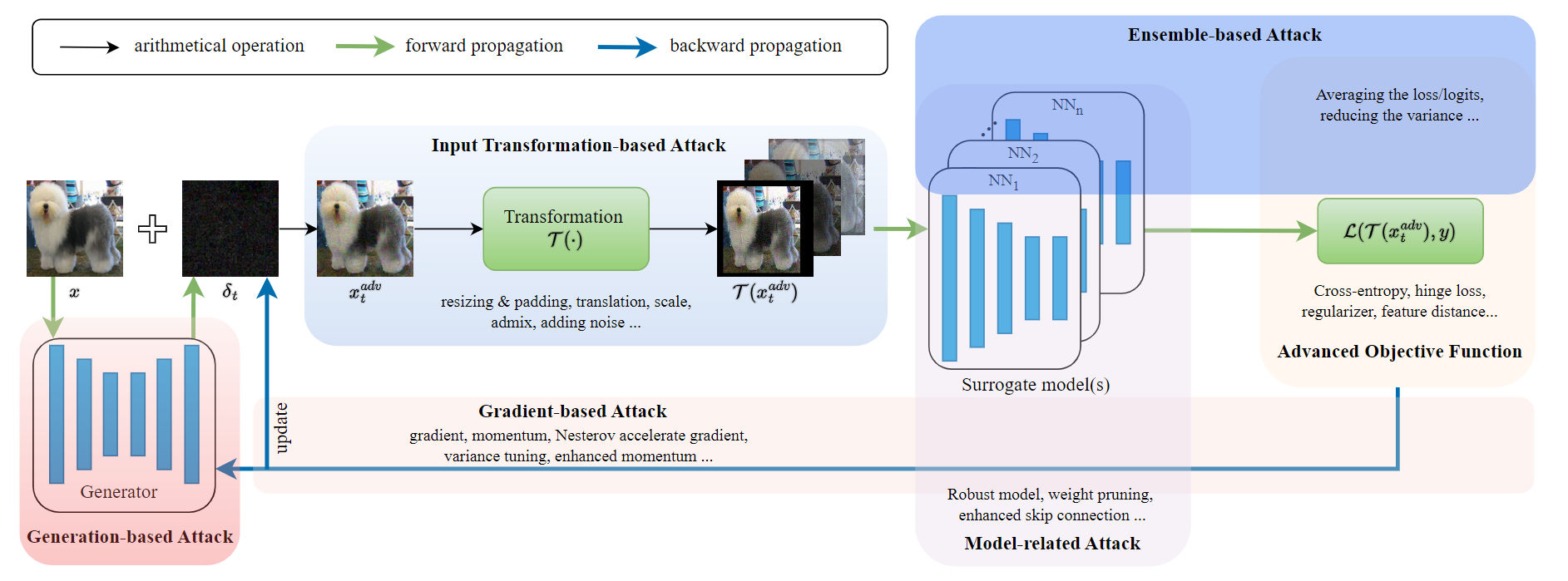
Enhancing targeted transferability via feature space fine-tuning
Adversarial examples (AEs) have been extensively studied due to their potential for privacy protection and inspiring robust neural networks. Yet, making a targeted AE transferable across unknown models remains challenging. In this paper, to alleviate the overfitting dilemma common in an AE crafted by existing simple iterative attacks, we propose fine-tuning it in the feature space. Specifically, starting with an AE generated by a baseline attack, we encourage the features conducive to the target class and discourage the features to the original class in a middle layer of the source model. Extensive experiments demonstrate that only a few iterations of fine-tuning can boost existing attacks' targeted transferability nontrivially and universally. Our results also verify that the simple iterative attacks can yield comparable or even better transferability than the resource-intensive methods, which rest on training target-specific classifiers or generators with additional data. The code is available at: github.com/zengh5/TA_feature_FT.
PDF Abstract
