Enhancing Vision-Language Pre-Training with Jointly Learned Questioner and Dense Captioner
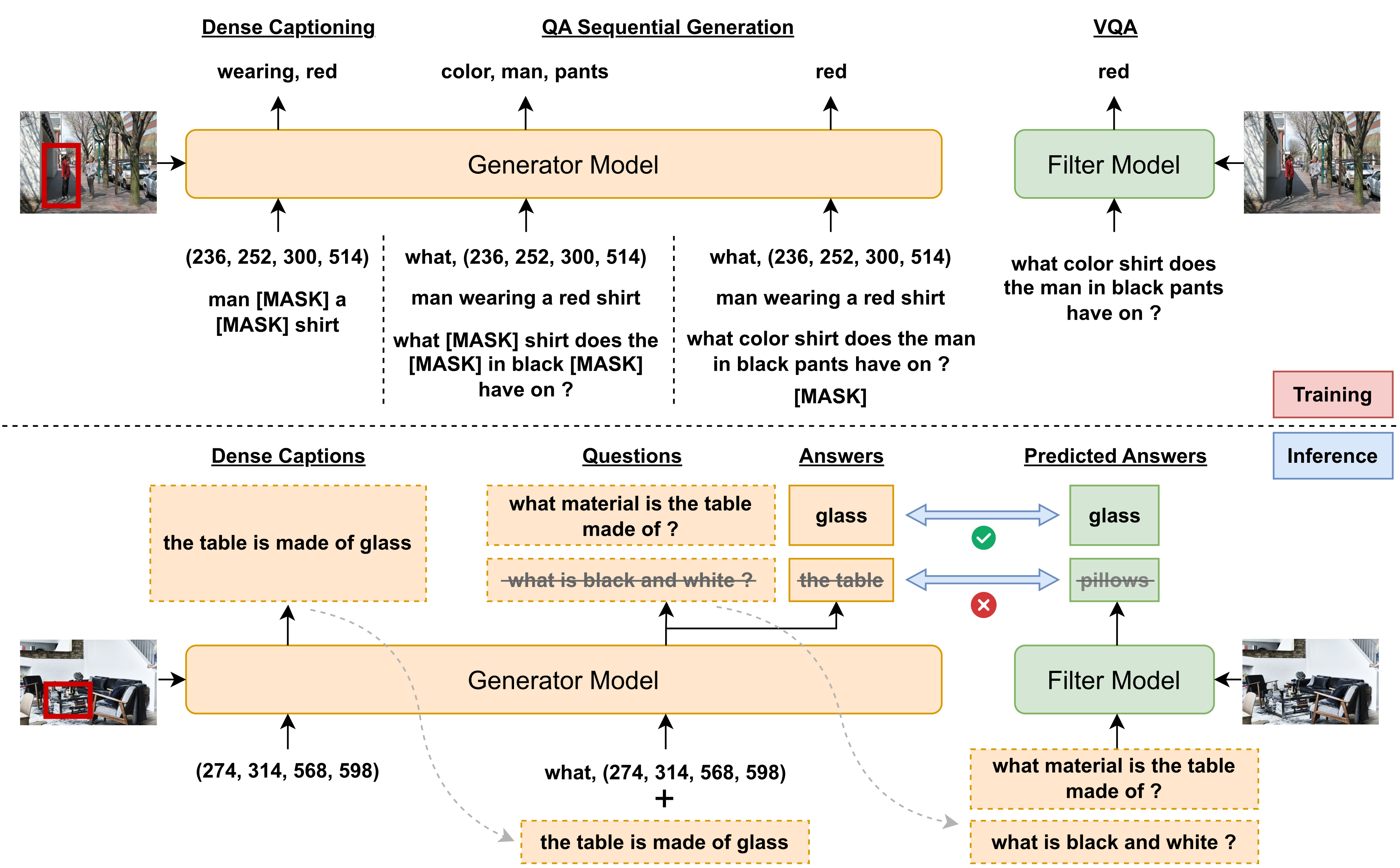
Large pre-trained multimodal models have demonstrated significant success in a range of downstream tasks, including image captioning, image-text retrieval, visual question answering (VQA), etc. However, many of these methods rely on image-text pairs collected from the web as pre-training data and unfortunately overlook the need for fine-grained feature alignment between vision and language modalities, which requires detailed understanding of images and language expressions. While integrating VQA and dense captioning (DC) into pre-training can address this issue, acquiring image-question-answer as well as image-location-caption triplets is challenging and time-consuming. Additionally, publicly available datasets for VQA and dense captioning are typically limited in scale due to manual data collection and labeling efforts. In this paper, we propose a novel method called Joint QA and DC GEneration (JADE), which utilizes a pre-trained multimodal model and easily-crawled image-text pairs to automatically generate and filter large-scale VQA and dense captioning datasets. We apply this method to the Conceptual Caption (CC3M) dataset to generate a new dataset called CC3M-QA-DC. Experiments show that when used for pre-training in a multi-task manner, CC3M-QA-DC can improve the performance with various backbones on various downstream tasks. Furthermore, our generated CC3M-QA-DC can be combined with larger image-text datasets (e.g., CC15M) and achieve competitive results compared with models using much more data. Code and dataset are available at https://github.com/johncaged/OPT_Questioner.
PDF Abstract




 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Visual Genome
Visual Genome
 Flickr30k
Flickr30k
 GQA
GQA
 Conceptual Captions
Conceptual Captions
 CC12M
CC12M
