EnvEdit: Environment Editing for Vision-and-Language Navigation
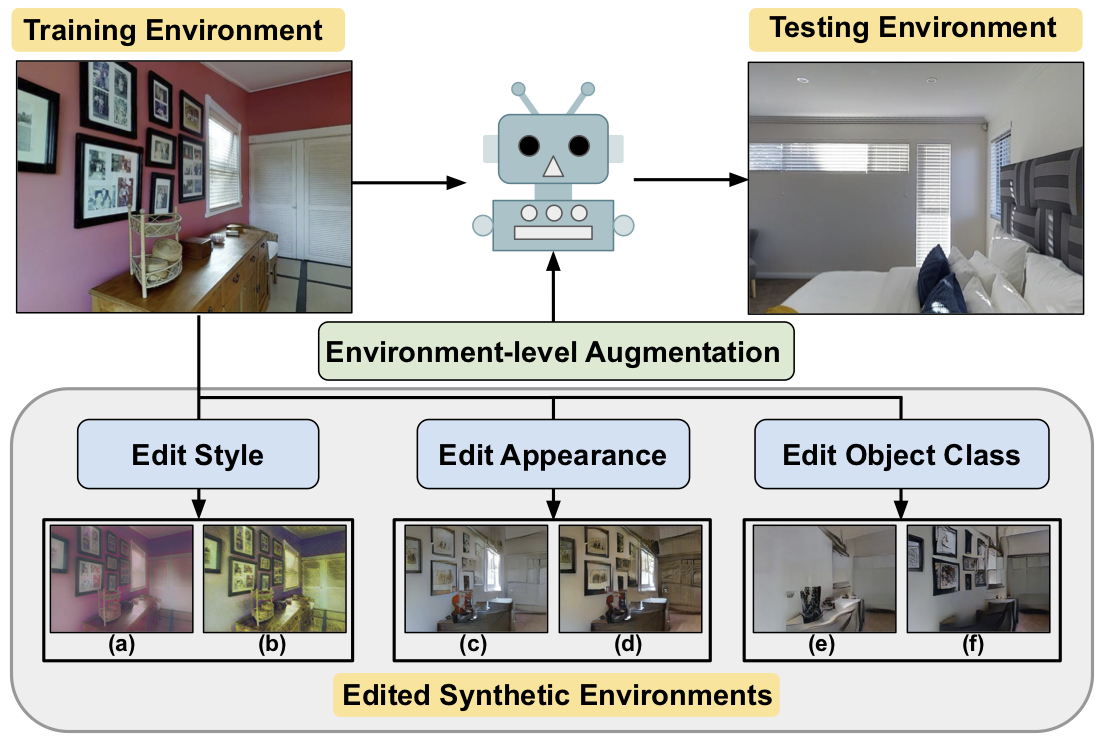
In Vision-and-Language Navigation (VLN), an agent needs to navigate through the environment based on natural language instructions. Due to limited available data for agent training and finite diversity in navigation environments, it is challenging for the agent to generalize to new, unseen environments. To address this problem, we propose EnvEdit, a data augmentation method that creates new environments by editing existing environments, which are used to train a more generalizable agent. Our augmented environments can differ from the seen environments in three diverse aspects: style, object appearance, and object classes. Training on these edit-augmented environments prevents the agent from overfitting to existing environments and helps generalize better to new, unseen environments. Empirically, on both the Room-to-Room and the multi-lingual Room-Across-Room datasets, we show that our proposed EnvEdit method gets significant improvements in all metrics on both pre-trained and non-pre-trained VLN agents, and achieves the new state-of-the-art on the test leaderboard. We further ensemble the VLN agents augmented on different edited environments and show that these edit methods are complementary. Code and data are available at https://github.com/jialuli-luka/EnvEdit
PDF Abstract CVPR 2022 PDF CVPR 2022 AbstractCode



 R2R
R2R
 RxR
RxR
Results from the Paper
 Ranked #2 on
Vision and Language Navigation
on RxR
(using extra training data)
Ranked #2 on
Vision and Language Navigation
on RxR
(using extra training data)
