FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
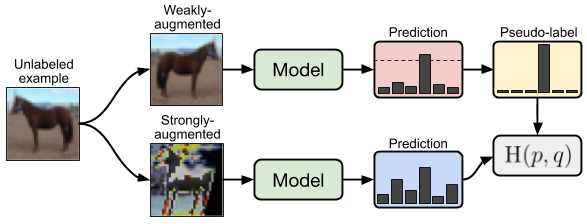
Semi-supervised learning (SSL) provides an effective means of leveraging unlabeled data to improve a model's performance. In this paper, we demonstrate the power of a simple combination of two common SSL methods: consistency regularization and pseudo-labeling. Our algorithm, FixMatch, first generates pseudo-labels using the model's predictions on weakly-augmented unlabeled images. For a given image, the pseudo-label is only retained if the model produces a high-confidence prediction. The model is then trained to predict the pseudo-label when fed a strongly-augmented version of the same image. Despite its simplicity, we show that FixMatch achieves state-of-the-art performance across a variety of standard semi-supervised learning benchmarks, including 94.93% accuracy on CIFAR-10 with 250 labels and 88.61% accuracy with 40 -- just 4 labels per class. Since FixMatch bears many similarities to existing SSL methods that achieve worse performance, we carry out an extensive ablation study to tease apart the experimental factors that are most important to FixMatch's success. We make our code available at https://github.com/google-research/fixmatch.
PDF Abstract NeurIPS 2020 PDF NeurIPS 2020 AbstractCode






 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 SVHN
SVHN
 STL-10
STL-10
Reproducibility Reports
FixMatch is a semi-supervised learning method, which achieves comparable results with fully supervised learning by leveraging a limited number of labeled data (pseudo labelling technique) and taking a good use of the unlabeled data (consistency regularization ). In this work, we reimplement FixMatch and achieve reasonably comparable performance with the official implementation, which supports that FixMatch outperforms semi-superivesed learning benchmarks and demonstrates that the authorʼs choices with respect to those ablations were experimentally sound. Next, we investigate the existence of a major problem of FixMatch, confirmation errors, by reconstructing the batch structure during the training process. It reveals existing confirmation errors, especially the ones caused by asymmetric noise in pseudo labels. To deal with the problem, we apply equal-frequency and confidence entropy regularization to the labeled data and add them in the loss function. Our experimental results on CIFAR-10 show that using either of the entropy regularization in the loss function can reduce the asymmetric noise in pseudo labels and improve the performance of FixMatch in the presence of (pseudo) labels containing (asymmetric) noise. Our code is available at the url: https://github.com/Celiali/FixMatch.

