FoolHD: Fooling speaker identification by Highly imperceptible adversarial Disturbances
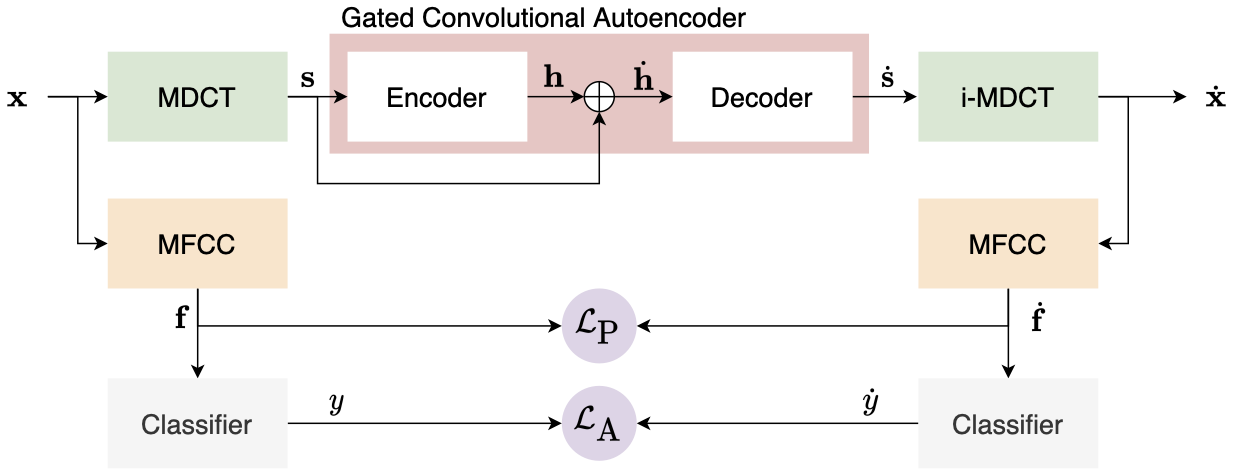
Speaker identification models are vulnerable to carefully designed adversarial perturbations of their input signals that induce misclassification. In this work, we propose a white-box steganography-inspired adversarial attack that generates imperceptible adversarial perturbations against a speaker identification model. Our approach, FoolHD, uses a Gated Convolutional Autoencoder that operates in the DCT domain and is trained with a multi-objective loss function, in order to generate and conceal the adversarial perturbation within the original audio files. In addition to hindering speaker identification performance, this multi-objective loss accounts for human perception through a frame-wise cosine similarity between MFCC feature vectors extracted from the original and adversarial audio files. We validate the effectiveness of FoolHD with a 250-speaker identification x-vector network, trained using VoxCeleb, in terms of accuracy, success rate, and imperceptibility. Our results show that FoolHD generates highly imperceptible adversarial audio files (average PESQ scores above 4.30), while achieving a success rate of 99.6% and 99.2% in misleading the speaker identification model, for untargeted and targeted settings, respectively.
PDF Abstract

 VoxCeleb1
VoxCeleb1
