FViT: A Focal Vision Transformer with Gabor Filter
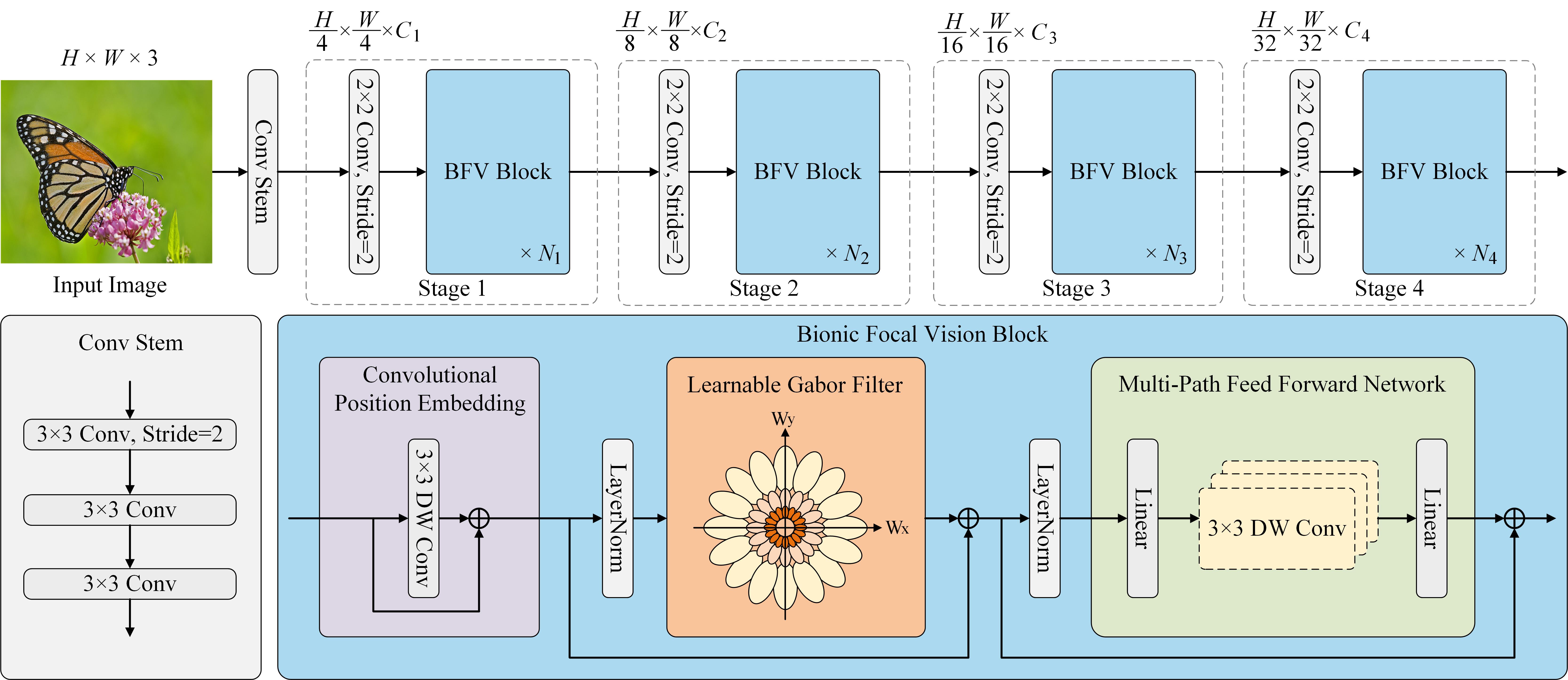
Vision transformers have achieved encouraging progress in various computer vision tasks. A common belief is that this is attributed to the competence of self-attention in modeling the global dependencies among feature tokens. Unfortunately, self-attention still faces some challenges in dense prediction tasks, such as the high computational complexity and absence of desirable inductive bias. To address these issues, we revisit the potential benefits of integrating vision transformer with Gabor filter, and propose a Learnable Gabor Filter (LGF) by using convolution. As an alternative to self-attention, we employ LGF to simulate the response of simple cells in the biological visual system to input images, prompting models to focus on discriminative feature representations of targets from various scales and orientations. Additionally, we design a Bionic Focal Vision (BFV) block based on the LGF. This block draws inspiration from neuroscience and introduces a Multi-Path Feed Forward Network (MPFFN) to emulate the working way of biological visual cortex processing information in parallel. Furthermore, we develop a unified and efficient pyramid backbone network family called Focal Vision Transformers (FViTs) by stacking BFV blocks. Experimental results show that FViTs exhibit highly competitive performance in various vision tasks. Especially in terms of computational efficiency and scalability, FViTs show significant advantages compared with other counterparts. Code is available at https://github.com/nkusyl/FViT
PDF Abstract

 MS COCO
MS COCO
 ADE20K
ADE20K
