GeoAuxNet: Towards Universal 3D Representation Learning for Multi-sensor Point Clouds
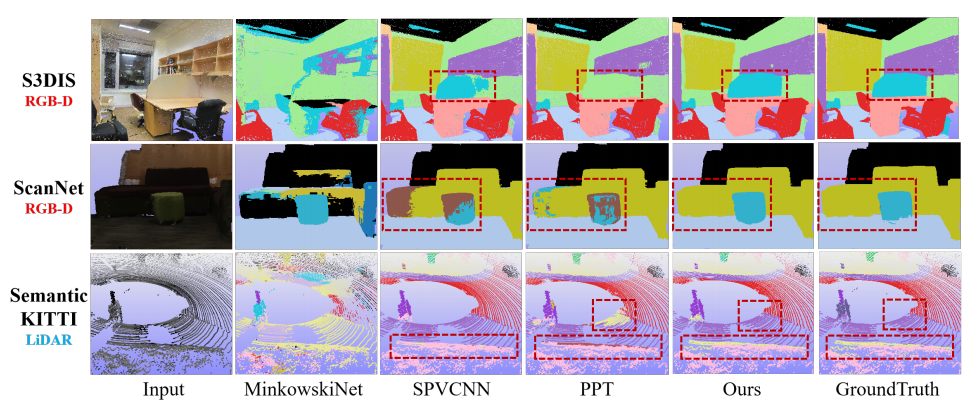
Point clouds captured by different sensors such as RGB-D cameras and LiDAR possess non-negligible domain gaps. Most existing methods design different network architectures and train separately on point clouds from various sensors. Typically, point-based methods achieve outstanding performances on even-distributed dense point clouds from RGB-D cameras, while voxel-based methods are more efficient for large-range sparse LiDAR point clouds. In this paper, we propose geometry-to-voxel auxiliary learning to enable voxel representations to access point-level geometric information, which supports better generalisation of the voxel-based backbone with additional interpretations of multi-sensor point clouds. Specifically, we construct hierarchical geometry pools generated by a voxel-guided dynamic point network, which efficiently provide auxiliary fine-grained geometric information adapted to different stages of voxel features. We conduct experiments on joint multi-sensor datasets to demonstrate the effectiveness of GeoAuxNet. Enjoying elaborate geometric information, our method outperforms other models collectively trained on multi-sensor datasets, and achieve competitive results with the-state-of-art experts on each single dataset.
PDF Abstract


 ScanNet
ScanNet
 SemanticKITTI
SemanticKITTI
 S3DIS
S3DIS
