Geometric Visual Similarity Learning in 3D Medical Image Self-supervised Pre-training
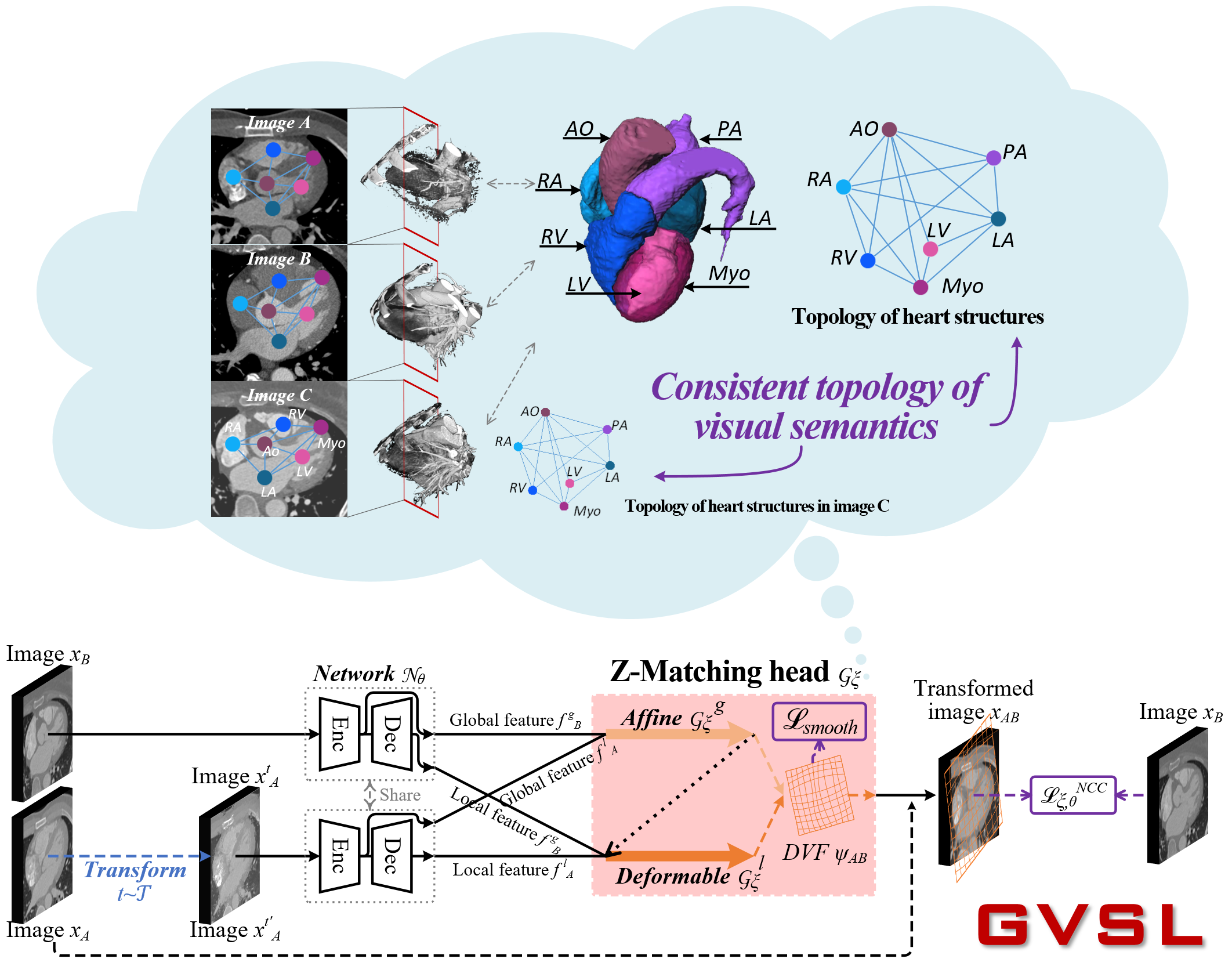
Learning inter-image similarity is crucial for 3D medical images self-supervised pre-training, due to their sharing of numerous same semantic regions. However, the lack of the semantic prior in metrics and the semantic-independent variation in 3D medical images make it challenging to get a reliable measurement for the inter-image similarity, hindering the learning of consistent representation for same semantics. We investigate the challenging problem of this task, i.e., learning a consistent representation between images for a clustering effect of same semantic features. We propose a novel visual similarity learning paradigm, Geometric Visual Similarity Learning, which embeds the prior of topological invariance into the measurement of the inter-image similarity for consistent representation of semantic regions. To drive this paradigm, we further construct a novel geometric matching head, the Z-matching head, to collaboratively learn the global and local similarity of semantic regions, guiding the efficient representation learning for different scale-level inter-image semantic features. Our experiments demonstrate that the pre-training with our learning of inter-image similarity yields more powerful inner-scene, inter-scene, and global-local transferring ability on four challenging 3D medical image tasks. Our codes and pre-trained models will be publicly available on https://github.com/YutingHe-list/GVSL.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract


