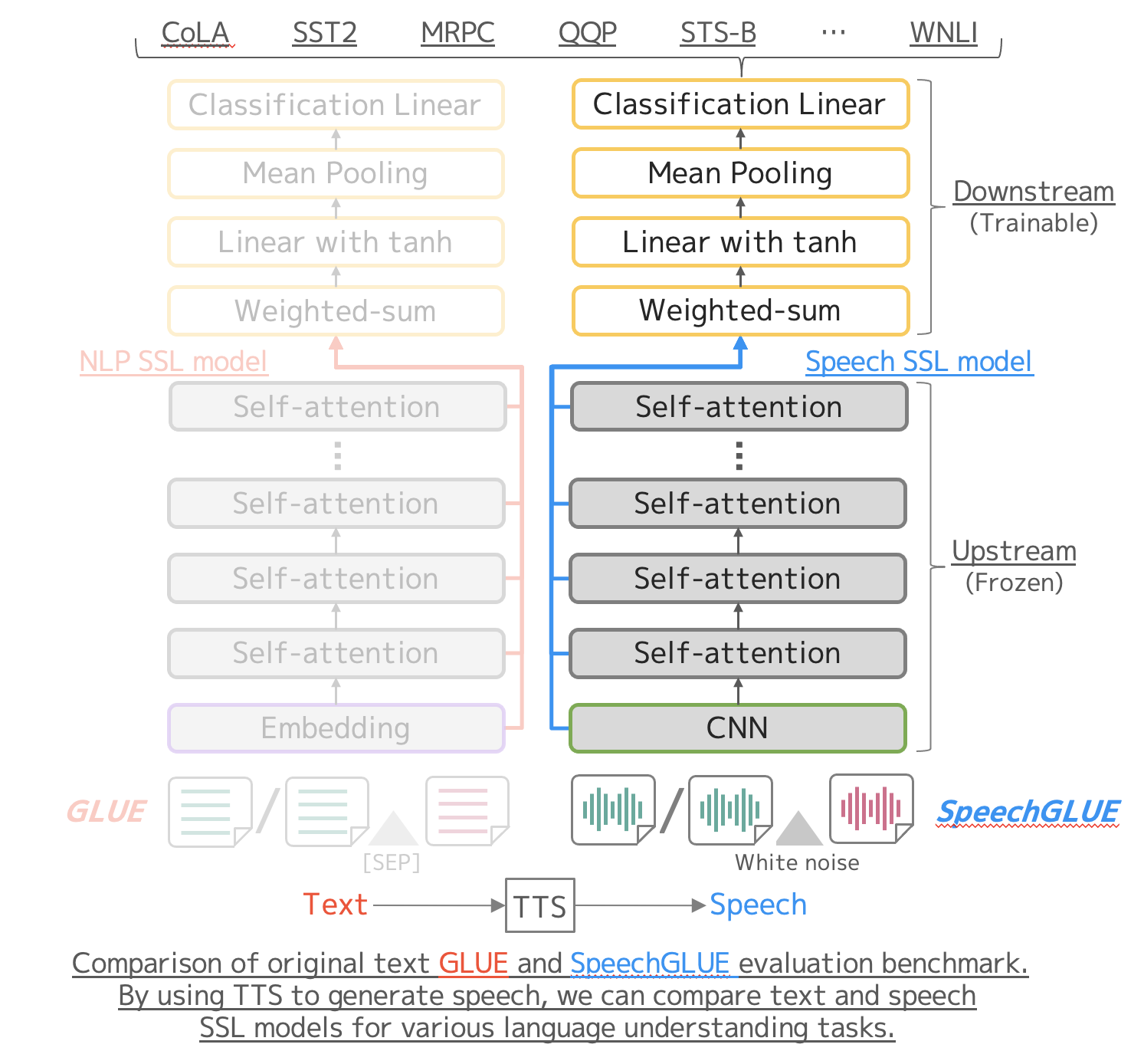
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
For natural language understanding (NLU) technology to be maximally useful, both practically and as a scientific object of study, it must be general: it must be able to process language in a way that is not exclusively tailored to any one specific task or dataset. In pursuit of this objective, we introduce the General Language Understanding Evaluation benchmark (GLUE), a tool for evaluating and analyzing the performance of models across a diverse range of existing NLU tasks. GLUE is model-agnostic, but it incentivizes sharing knowledge across tasks because certain tasks have very limited training data. We further provide a hand-crafted diagnostic test suite that enables detailed linguistic analysis of NLU models. We evaluate baselines based on current methods for multi-task and transfer learning and find that they do not immediately give substantial improvements over the aggregate performance of training a separate model per task, indicating room for improvement in developing general and robust NLU systems.
PDF Abstract WS 2018 PDF WS 2018 Abstract

 Colab
Colab



 GLUE
GLUE
 QNLI
QNLI
 SST
SST
 MultiNLI
MultiNLI
 SNLI
SNLI
 MRPC
MRPC
 CoLA
CoLA
 WSC
WSC
 SentEval
SentEval
 Quora Question Pairs
Quora Question Pairs

