Graph Contrastive Learning for Skeleton-based Action Recognition
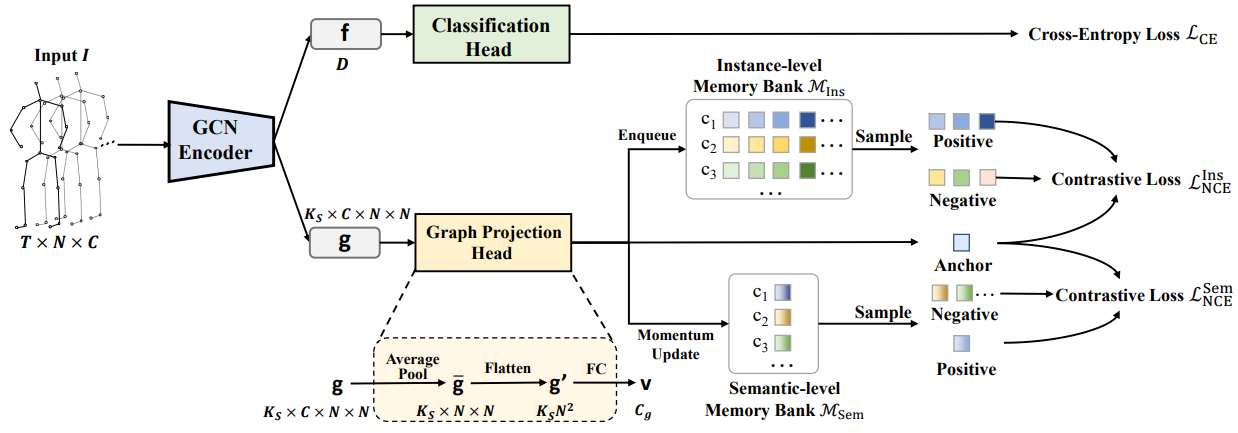
In the field of skeleton-based action recognition, current top-performing graph convolutional networks (GCNs) exploit intra-sequence context to construct adaptive graphs for feature aggregation. However, we argue that such context is still \textit{local} since the rich cross-sequence relations have not been explicitly investigated. In this paper, we propose a graph contrastive learning framework for skeleton-based action recognition (\textit{SkeletonGCL}) to explore the \textit{global} context across all sequences. In specific, SkeletonGCL associates graph learning across sequences by enforcing graphs to be class-discriminative, \emph{i.e.,} intra-class compact and inter-class dispersed, which improves the GCN capacity to distinguish various action patterns. Besides, two memory banks are designed to enrich cross-sequence context from two complementary levels, \emph{i.e.,} instance and semantic levels, enabling graph contrastive learning in multiple context scales. Consequently, SkeletonGCL establishes a new training paradigm, and it can be seamlessly incorporated into current GCNs. Without loss of generality, we combine SkeletonGCL with three GCNs (2S-ACGN, CTR-GCN, and InfoGCN), and achieve consistent improvements on NTU60, NTU120, and NW-UCLA benchmarks. The source code will be available at \url{https://github.com/OliverHxh/SkeletonGCL}.
PDF AbstractCode





Datasets
 NTU RGB+D
NTU RGB+D
 NTU RGB+D 120
NTU RGB+D 120
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Skeleton Based Action Recognition | NTU RGB+D | SkeletonGCL (based on CTR-GCN) | Accuracy (CV) | 97.0 | # 14 | |
| Accuracy (CS) | 93.1 | # 9 | ||||
| Ensembled Modalities | 4 | # 2 | ||||
| Skeleton Based Action Recognition | NTU RGB+D 120 | SkeletonGCL (based on CTR-GCN) | Accuracy (Cross-Subject) | 89.5 | # 12 | |
| Accuracy (Cross-Setup) | 91.0 | # 12 | ||||
| Ensembled Modalities | 4 | # 1 |
