Guiding Monocular Depth Estimation Using Depth-Attention Volume
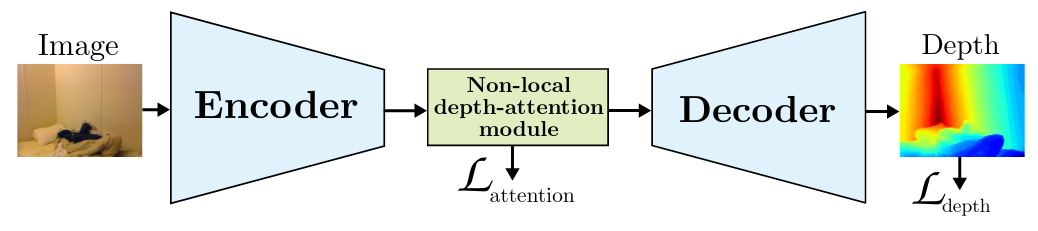
Recovering the scene depth from a single image is an ill-posed problem that requires additional priors, often referred to as monocular depth cues, to disambiguate different 3D interpretations. In recent works, those priors have been learned in an end-to-end manner from large datasets by using deep neural networks. In this paper, we propose guiding depth estimation to favor planar structures that are ubiquitous especially in indoor environments. This is achieved by incorporating a non-local coplanarity constraint to the network with a novel attention mechanism called depth-attention volume (DAV). Experiments on two popular indoor datasets, namely NYU-Depth-v2 and ScanNet, show that our method achieves state-of-the-art depth estimation results while using only a fraction of the number of parameters needed by the competing methods.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract


 ScanNet
ScanNet
 SUN RGB-D
SUN RGB-D
