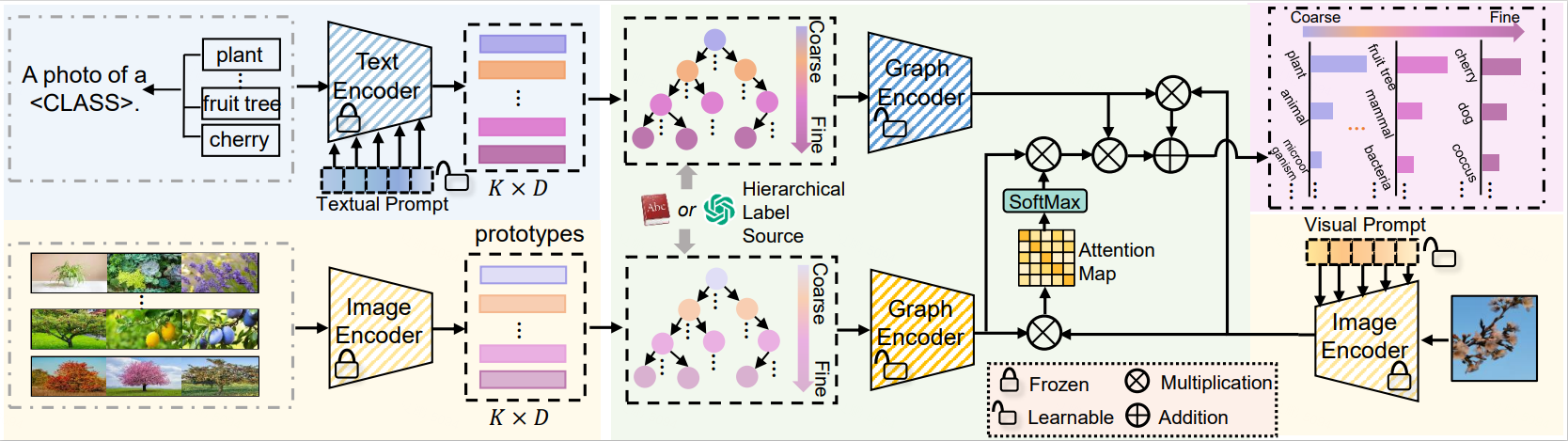
HGCLIP: Exploring Vision-Language Models with Graph Representations for Hierarchical Understanding
Object categories are typically organized into a multi-granularity taxonomic hierarchy. When classifying categories at different hierarchy levels, traditional uni-modal approaches focus primarily on image features, revealing limitations in complex scenarios. Recent studies integrating Vision-Language Models (VLMs) with class hierarchies have shown promise, yet they fall short of fully exploiting the hierarchical relationships. These efforts are constrained by their inability to perform effectively across varied granularity of categories. To tackle this issue, we propose a novel framework (HGCLIP) that effectively combines CLIP with a deeper exploitation of the Hierarchical class structure via Graph representation learning. We explore constructing the class hierarchy into a graph, with its nodes representing the textual or image features of each category. After passing through a graph encoder, the textual features incorporate hierarchical structure information, while the image features emphasize class-aware features derived from prototypes through the attention mechanism. Our approach demonstrates significant improvements on 11 diverse visual recognition benchmarks. Our codes are fully available at https://github.com/richard-peng-xia/HGCLIP.
PDF Abstract


 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 Stanford Cars
Stanford Cars
 DTD
DTD
 Food-101
Food-101
 Caltech-101
Caltech-101
 EuroSAT
EuroSAT
 FGVC-Aircraft
FGVC-Aircraft
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
 Oxford-IIIT Pet Dataset
Oxford-IIIT Pet Dataset
 ETHEC
ETHEC
 Fruits 360
Fruits 360
