HiMAP: Learning Heuristics-Informed Policies for Large-Scale Multi-Agent Pathfinding
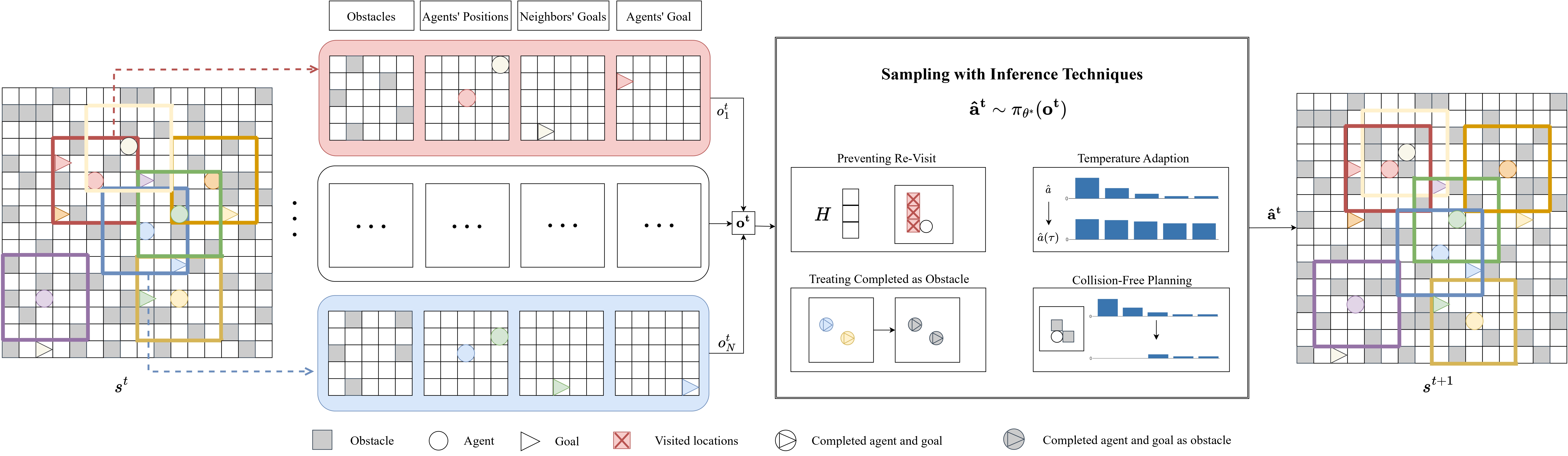
Large-scale multi-agent pathfinding (MAPF) presents significant challenges in several areas. As systems grow in complexity with a multitude of autonomous agents operating simultaneously, efficient and collision-free coordination becomes paramount. Traditional algorithms often fall short in scalability, especially in intricate scenarios. Reinforcement Learning (RL) has shown potential to address the intricacies of MAPF; however, it has also been shown to struggle with scalability, demanding intricate implementation, lengthy training, and often exhibiting unstable convergence, limiting its practical application. In this paper, we introduce Heuristics-Informed Multi-Agent Pathfinding (HiMAP), a novel scalable approach that employs imitation learning with heuristic guidance in a decentralized manner. We train on small-scale instances using a heuristic policy as a teacher that maps each single agent observation information to an action probability distribution. During pathfinding, we adopt several inference techniques to improve performance. With a simple training scheme and implementation, HiMAP demonstrates competitive results in terms of success rate and scalability in the field of imitation-learning-only MAPF, showing the potential of imitation-learning-only MAPF equipped with inference techniques.
PDF Abstract

