Honeybee: Locality-enhanced Projector for Multimodal LLM
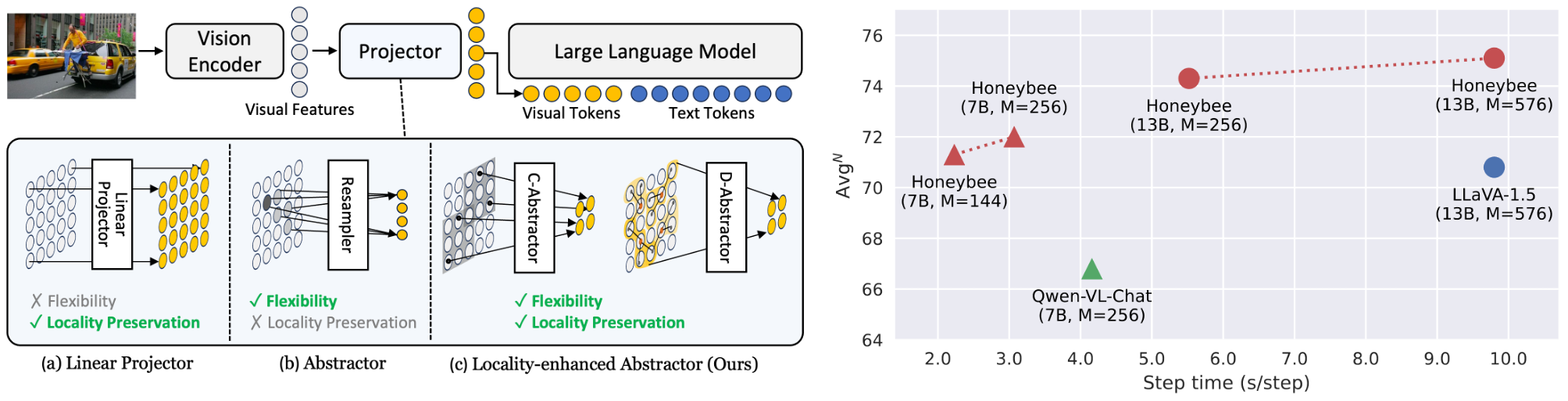
In Multimodal Large Language Models (MLLMs), a visual projector plays a crucial role in bridging pre-trained vision encoders with LLMs, enabling profound visual understanding while harnessing the LLMs' robust capabilities. Despite the importance of the visual projector, it has been relatively less explored. In this study, we first identify two essential projector properties: (i) flexibility in managing the number of visual tokens, crucial for MLLMs' overall efficiency, and (ii) preservation of local context from visual features, vital for spatial understanding. Based on these findings, we propose a novel projector design that is both flexible and locality-enhanced, effectively satisfying the two desirable properties. Additionally, we present comprehensive strategies to effectively utilize multiple and multifaceted instruction datasets. Through extensive experiments, we examine the impact of individual design choices. Finally, our proposed MLLM, Honeybee, remarkably outperforms previous state-of-the-art methods across various benchmarks, including MME, MMBench, SEED-Bench, and LLaVA-Bench, achieving significantly higher efficiency. Code and models are available at https://github.com/kakaobrain/honeybee.
PDF AbstractCode


Datasets
 GQA
GQA
 RefCOCO
RefCOCO
 ScienceQA
ScienceQA
 MMBench
MMBench
 SEED-Bench
SEED-Bench
Results from the Paper
 Ranked #1 on
Science Question Answering
on ScienceQA
(using extra training data)
Ranked #1 on
Science Question Answering
on ScienceQA
(using extra training data)
