If at First You Don't Succeed, Try, Try Again: Faithful Diffusion-based Text-to-Image Generation by Selection
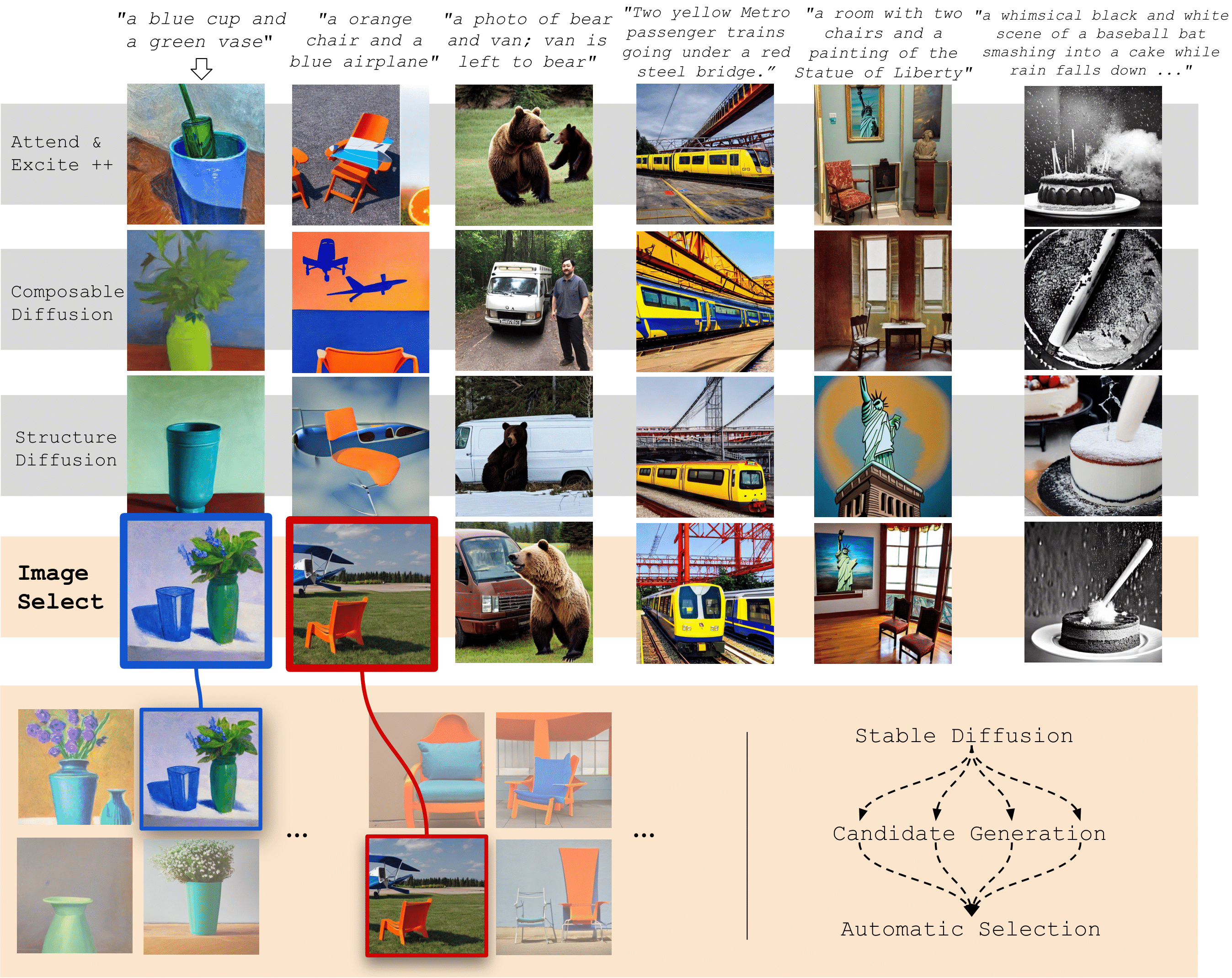
Despite their impressive capabilities, diffusion-based text-to-image (T2I) models can lack faithfulness to the text prompt, where generated images may not contain all the mentioned objects, attributes or relations. To alleviate these issues, recent works proposed post-hoc methods to improve model faithfulness without costly retraining, by modifying how the model utilizes the input prompt. In this work, we take a step back and show that large T2I diffusion models are more faithful than usually assumed, and can generate images faithful to even complex prompts without the need to manipulate the generative process. Based on that, we show how faithfulness can be simply treated as a candidate selection problem instead, and introduce a straightforward pipeline that generates candidate images for a text prompt and picks the best one according to an automatic scoring system that can leverage already existing T2I evaluation metrics. Quantitative comparisons alongside user studies on diverse benchmarks show consistently improved faithfulness over post-hoc enhancement methods, with comparable or lower computational cost. Code is available at \url{https://github.com/ExplainableML/ImageSelect}.
PDF Abstract


 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
