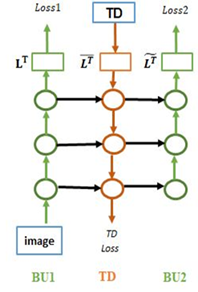
Image interpretation by iterative bottom-up top-down processing
Scene understanding requires the extraction and representation of scene components together with their properties and inter-relations. We describe a model in which meaningful scene structures are extracted from the image by an iterative process, combining bottom-up (BU) and top-down (TD) networks, interacting through a symmetric bi-directional communication between them (counter-streams structure). The model constructs a scene representation by the iterative use of three components. The first model component is a BU stream that extracts selected scene elements, properties and relations. The second component (cognitive augmentation) augments the extracted visual representation based on relevant non-visual stored representations. It also provides input to the third component, the TD stream, in the form of a TD instruction, instructing the model what task to perform next. The TD stream then guides the BU visual stream to perform the selected task in the next cycle. During this process, the visual representations extracted from the image can be combined with relevant non-visual representations, so that the final scene representation is based on both visual information extracted from the scene and relevant stored knowledge of the world. We describe how a sequence of TD-instructions is used to extract from the scene structures of interest, including an algorithm to automatically select the next TD-instruction in the sequence. The extraction process is shown to have favorable properties in terms of combinatorial generalization, generalizing well to novel scene structures and new combinations of objects, properties and relations not seen during training. Finally, we compare the model with relevant aspects of the human vision, and suggest directions for using the BU-TD scheme for integrating visual and cognitive components in the process of scene understanding.
PDF Abstract

 MNIST
MNIST
 CUB-200-2011
CUB-200-2011
 CLEVR
CLEVR
 MultiMNIST
MultiMNIST
