IMos: Intent-Driven Full-Body Motion Synthesis for Human-Object Interactions
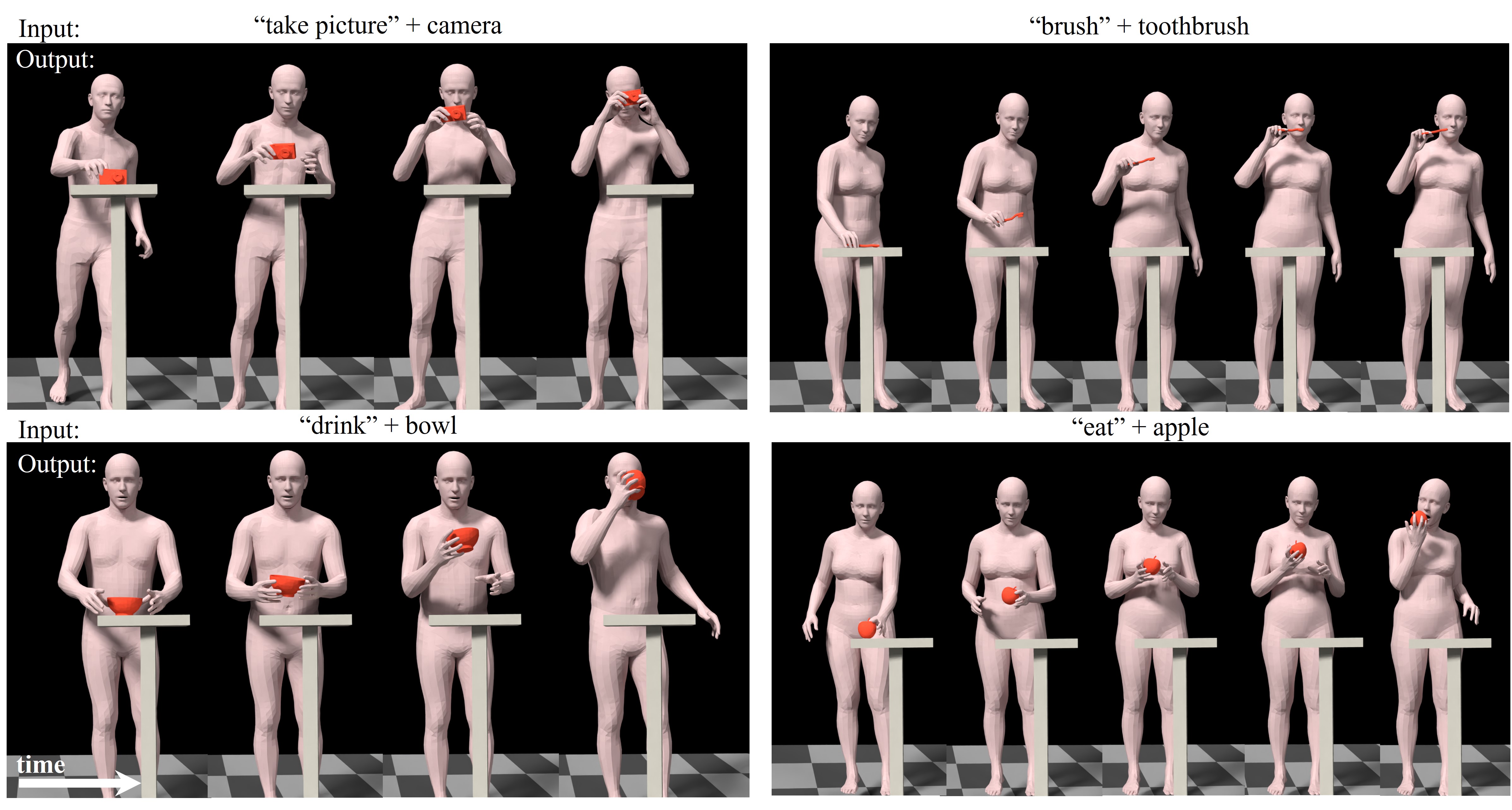
Can we make virtual characters in a scene interact with their surrounding objects through simple instructions? Is it possible to synthesize such motion plausibly with a diverse set of objects and instructions? Inspired by these questions, we present the first framework to synthesize the full-body motion of virtual human characters performing specified actions with 3D objects placed within their reach. Our system takes textual instructions specifying the objects and the associated intentions of the virtual characters as input and outputs diverse sequences of full-body motions. This contrasts existing works, where full-body action synthesis methods generally do not consider object interactions, and human-object interaction methods focus mainly on synthesizing hand or finger movements for grasping objects. We accomplish our objective by designing an intent-driven fullbody motion generator, which uses a pair of decoupled conditional variational auto-regressors to learn the motion of the body parts in an autoregressive manner. We also optimize the 6-DoF pose of the objects such that they plausibly fit within the hands of the synthesized characters. We compare our proposed method with the existing methods of motion synthesis and establish a new and stronger state-of-the-art for the task of intent-driven motion synthesis.
PDF Abstract


 GRAB
GRAB
