Improving Bilingual Lexicon Induction with Cross-Encoder Reranking
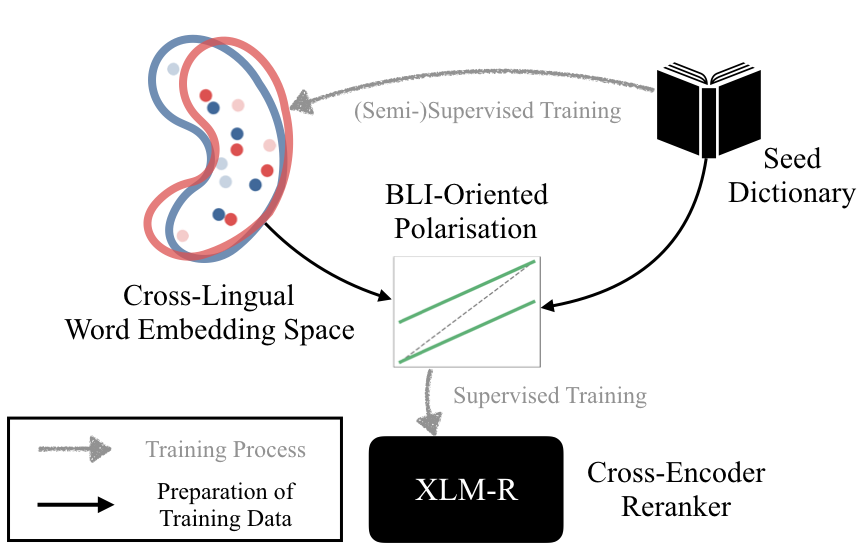
Bilingual lexicon induction (BLI) with limited bilingual supervision is a crucial yet challenging task in multilingual NLP. Current state-of-the-art BLI methods rely on the induction of cross-lingual word embeddings (CLWEs) to capture cross-lingual word similarities; such CLWEs are obtained 1) via traditional static models (e.g., VecMap), or 2) by extracting type-level CLWEs from multilingual pretrained language models (mPLMs), or 3) through combining the former two options. In this work, we propose a novel semi-supervised post-hoc reranking method termed BLICEr (BLI with Cross-Encoder Reranking), applicable to any precalculated CLWE space, which improves their BLI capability. The key idea is to 'extract' cross-lingual lexical knowledge from mPLMs, and then combine it with the original CLWEs. This crucial step is done via 1) creating a word similarity dataset, comprising positive word pairs (i.e., true translations) and hard negative pairs induced from the original CLWE space, and then 2) fine-tuning an mPLM (e.g., mBERT or XLM-R) in a cross-encoder manner to predict the similarity scores. At inference, we 3) combine the similarity score from the original CLWE space with the score from the BLI-tuned cross-encoder. BLICEr establishes new state-of-the-art results on two standard BLI benchmarks spanning a wide spectrum of diverse languages: it substantially outperforms a series of strong baselines across the board. We also validate the robustness of BLICEr with different CLWEs.
PDF Abstract



