Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data
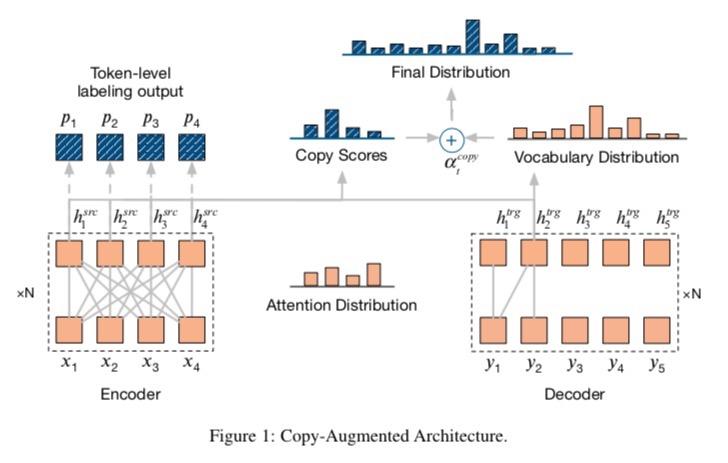
Neural machine translation systems have become state-of-the-art approaches for Grammatical Error Correction (GEC) task. In this paper, we propose a copy-augmented architecture for the GEC task by copying the unchanged words from the source sentence to the target sentence. Since the GEC suffers from not having enough labeled training data to achieve high accuracy. We pre-train the copy-augmented architecture with a denoising auto-encoder using the unlabeled One Billion Benchmark and make comparisons between the fully pre-trained model and a partially pre-trained model. It is the first time copying words from the source context and fully pre-training a sequence to sequence model are experimented on the GEC task. Moreover, We add token-level and sentence-level multi-task learning for the GEC task. The evaluation results on the CoNLL-2014 test set show that our approach outperforms all recently published state-of-the-art results by a large margin. The code and pre-trained models are released at https://github.com/zhawe01/fairseq-gec.
PDF Abstract NAACL 2019 PDF NAACL 2019 Abstract





 JFLEG
JFLEG
 CoNLL-2014 Shared Task: Grammatical Error Correction
CoNLL-2014 Shared Task: Grammatical Error Correction

