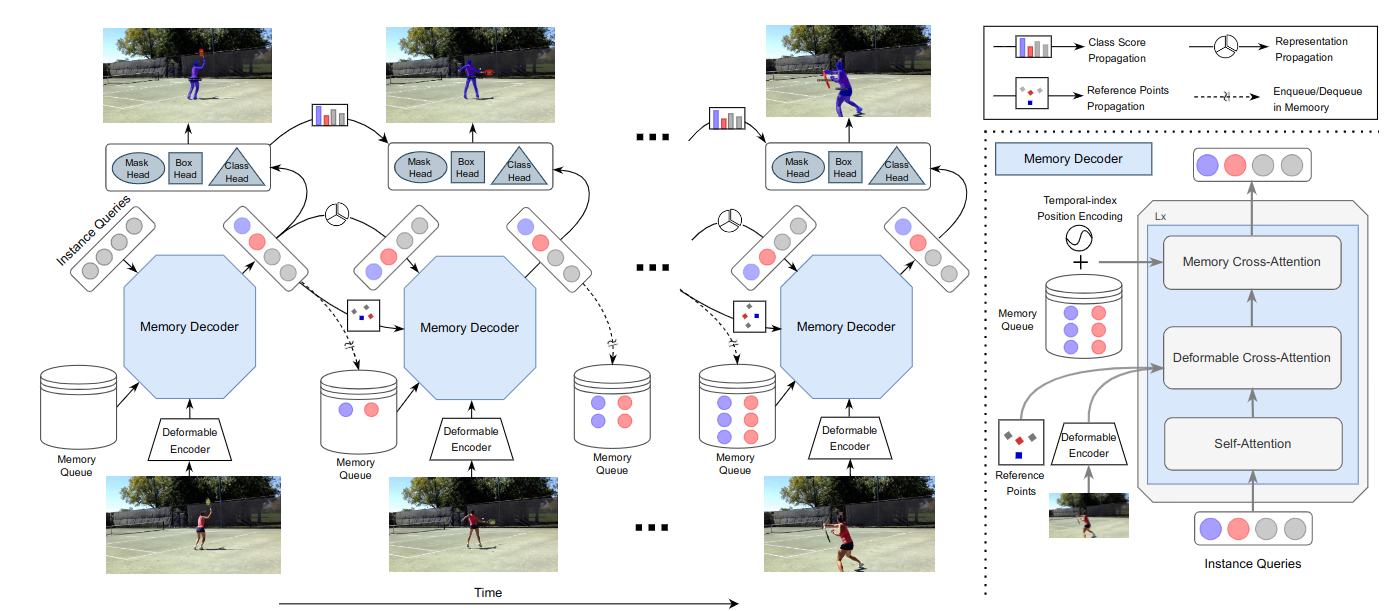
InstanceFormer: An Online Video Instance Segmentation Framework
Recent transformer-based offline video instance segmentation (VIS) approaches achieve encouraging results and significantly outperform online approaches. However, their reliance on the whole video and the immense computational complexity caused by full Spatio-temporal attention limit them in real-life applications such as processing lengthy videos. In this paper, we propose a single-stage transformer-based efficient online VIS framework named InstanceFormer, which is especially suitable for long and challenging videos. We propose three novel components to model short-term and long-term dependency and temporal coherence. First, we propagate the representation, location, and semantic information of prior instances to model short-term changes. Second, we propose a novel memory cross-attention in the decoder, which allows the network to look into earlier instances within a certain temporal window. Finally, we employ a temporal contrastive loss to impose coherence in the representation of an instance across all frames. Memory attention and temporal coherence are particularly beneficial to long-range dependency modeling, including challenging scenarios like occlusion. The proposed InstanceFormer outperforms previous online benchmark methods by a large margin across multiple datasets. Most importantly, InstanceFormer surpasses offline approaches for challenging and long datasets such as YouTube-VIS-2021 and OVIS. Code is available at https://github.com/rajatkoner08/InstanceFormer.
PDF Abstract



 YouTube-VIS 2019
YouTube-VIS 2019
 OVIS
OVIS
 Youtube-VIS 2022 Validation
Youtube-VIS 2022 Validation
Results from the Paper
 Ranked #5 on
Video Instance Segmentation
on Youtube-VIS 2022 Validation
(using extra training data)
Ranked #5 on
Video Instance Segmentation
on Youtube-VIS 2022 Validation
(using extra training data)
