Interpretable Visual Reasoning via Induced Symbolic Space
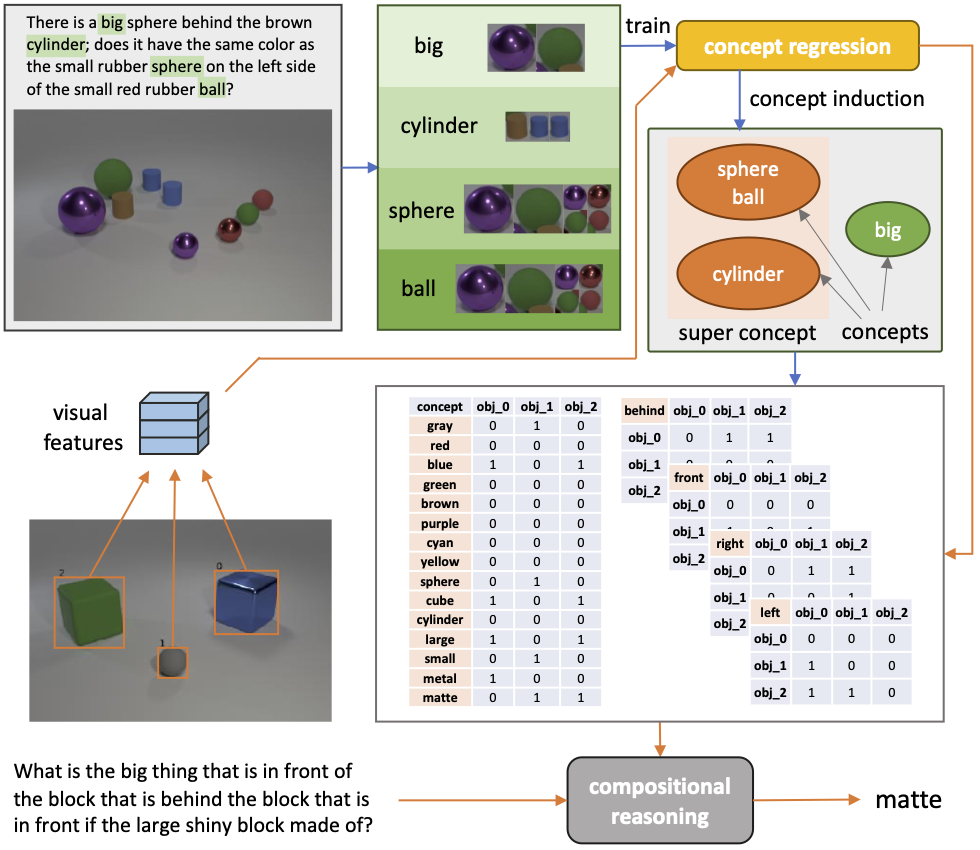
We study the problem of concept induction in visual reasoning, i.e., identifying concepts and their hierarchical relationships from question-answer pairs associated with images; and achieve an interpretable model via working on the induced symbolic concept space. To this end, we first design a new framework named object-centric compositional attention model (OCCAM) to perform the visual reasoning task with object-level visual features. Then, we come up with a method to induce concepts of objects and relations using clues from the attention patterns between objects' visual features and question words. Finally, we achieve a higher level of interpretability by imposing OCCAM on the objects represented in the induced symbolic concept space. Our model design makes this an easy adaption via first predicting the concepts of objects and relations and then projecting the predicted concepts back to the visual feature space so the compositional reasoning module can process normally. Experiments on the CLEVR and GQA datasets demonstrate: 1) our OCCAM achieves a new state of the art without human-annotated functional programs; 2) our induced concepts are both accurate and sufficient as OCCAM achieves an on-par performance on objects represented either in visual features or in the induced symbolic concept space.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract

 Visual Question Answering
Visual Question Answering
 CLEVR
CLEVR
 GQA
GQA

