It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners
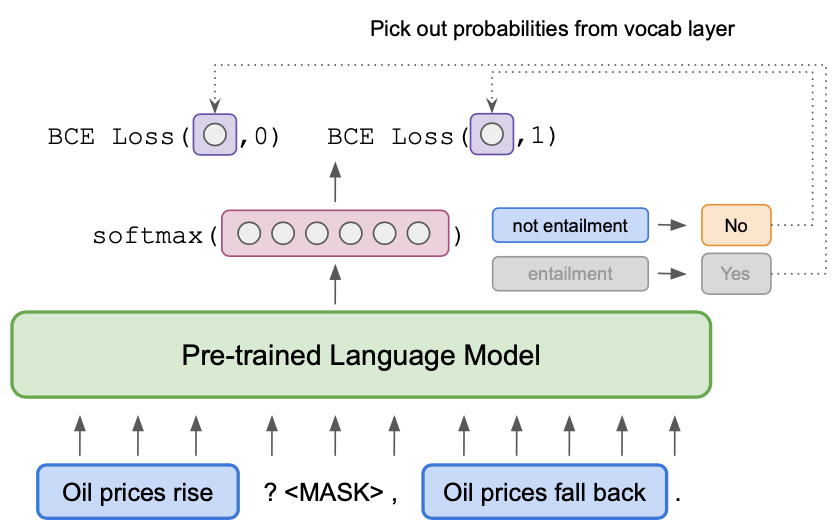
When scaled to hundreds of billions of parameters, pretrained language models such as GPT-3 (Brown et al., 2020) achieve remarkable few-shot performance. However, enormous amounts of compute are required for training and applying such big models, resulting in a large carbon footprint and making it difficult for researchers and practitioners to use them. We show that performance similar to GPT-3 can be obtained with language models that are much "greener" in that their parameter count is several orders of magnitude smaller. This is achieved by converting textual inputs into cloze questions that contain a task description, combined with gradient-based optimization; exploiting unlabeled data gives further improvements. We identify key factors required for successful natural language understanding with small language models.
PDF Abstract NAACL 2021 PDF NAACL 2021 Abstract
 Colab
Colab

 MultiNLI
MultiNLI
 BoolQ
BoolQ
 SuperGLUE
SuperGLUE
 WSC
WSC
 COPA
COPA
 MultiRC
MultiRC
 ReCoRD
ReCoRD
