K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters
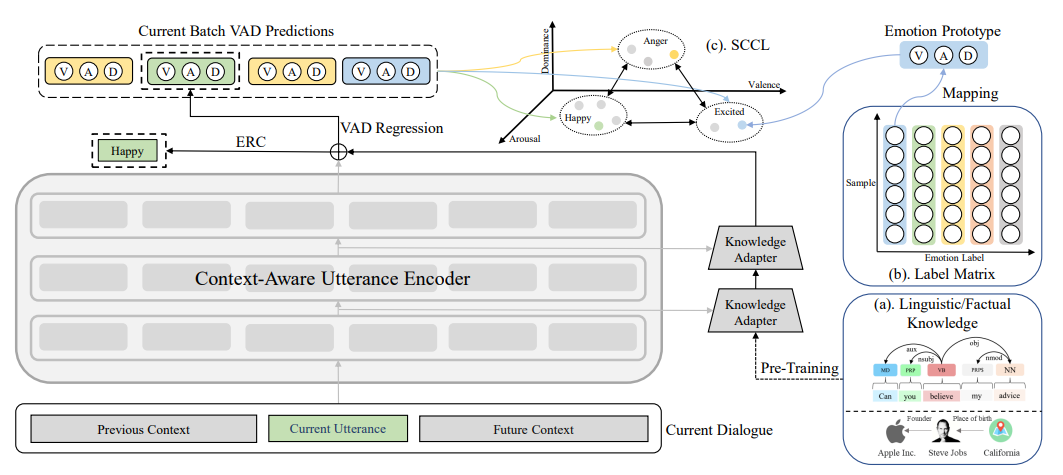
We study the problem of injecting knowledge into large pre-trained models like BERT and RoBERTa. Existing methods typically update the original parameters of pre-trained models when injecting knowledge. However, when multiple kinds of knowledge are injected, the historically injected knowledge would be flushed away. To address this, we propose K-Adapter, a framework that retains the original parameters of the pre-trained model fixed and supports the development of versatile knowledge-infused model. Taking RoBERTa as the backbone model, K-Adapter has a neural adapter for each kind of infused knowledge, like a plug-in connected to RoBERTa. There is no information flow between different adapters, thus multiple adapters can be efficiently trained in a distributed way. As a case study, we inject two kinds of knowledge in this work, including (1) factual knowledge obtained from automatically aligned text-triplets on Wikipedia and Wikidata and (2) linguistic knowledge obtained via dependency parsing. Results on three knowledge-driven tasks, including relation classification, entity typing, and question answering, demonstrate that each adapter improves the performance and the combination of both adapters brings further improvements. Further analysis indicates that K-Adapter captures versatile knowledge than RoBERTa.
PDF Abstract Findings (ACL) 2021 PDF Findings (ACL) 2021 Abstract




 TACRED
TACRED
 SearchQA
SearchQA
 CosmosQA
CosmosQA
 QUASAR-T
QUASAR-T
 QUASAR
QUASAR
 Open Entity
Open Entity

