KART: Parameterization of Privacy Leakage Scenarios from Pre-trained Language Models
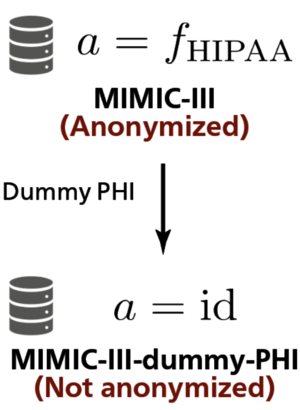
For the safe sharing pre-trained language models, no guidelines exist at present owing to the difficulty in estimating the upper bound of the risk of privacy leakage. One problem is that previous studies have assessed the risk for different real-world privacy leakage scenarios and attack methods, which reduces the portability of the findings. To tackle this problem, we represent complex real-world privacy leakage scenarios under a universal parameterization, \textit{Knowledge, Anonymization, Resource, and Target} (KART). KART parameterization has two merits: (i) it clarifies the definition of privacy leakage in each experiment and (ii) it improves the comparability of the findings of risk assessments. We show that previous studies can be simply reviewed by parameterizing the scenarios with KART. We also demonstrate privacy risk assessments in different scenarios under the same attack method, which suggests that KART helps approximate the upper bound of risk under a specific attack or scenario. We believe that KART helps integrate past and future findings on privacy risk and will contribute to a standard for sharing language models.
PDF Abstract MIMIC-III
MIMIC-III
