Tell, Draw, and Repeat: Generating and Modifying Images Based on Continual Linguistic Instruction
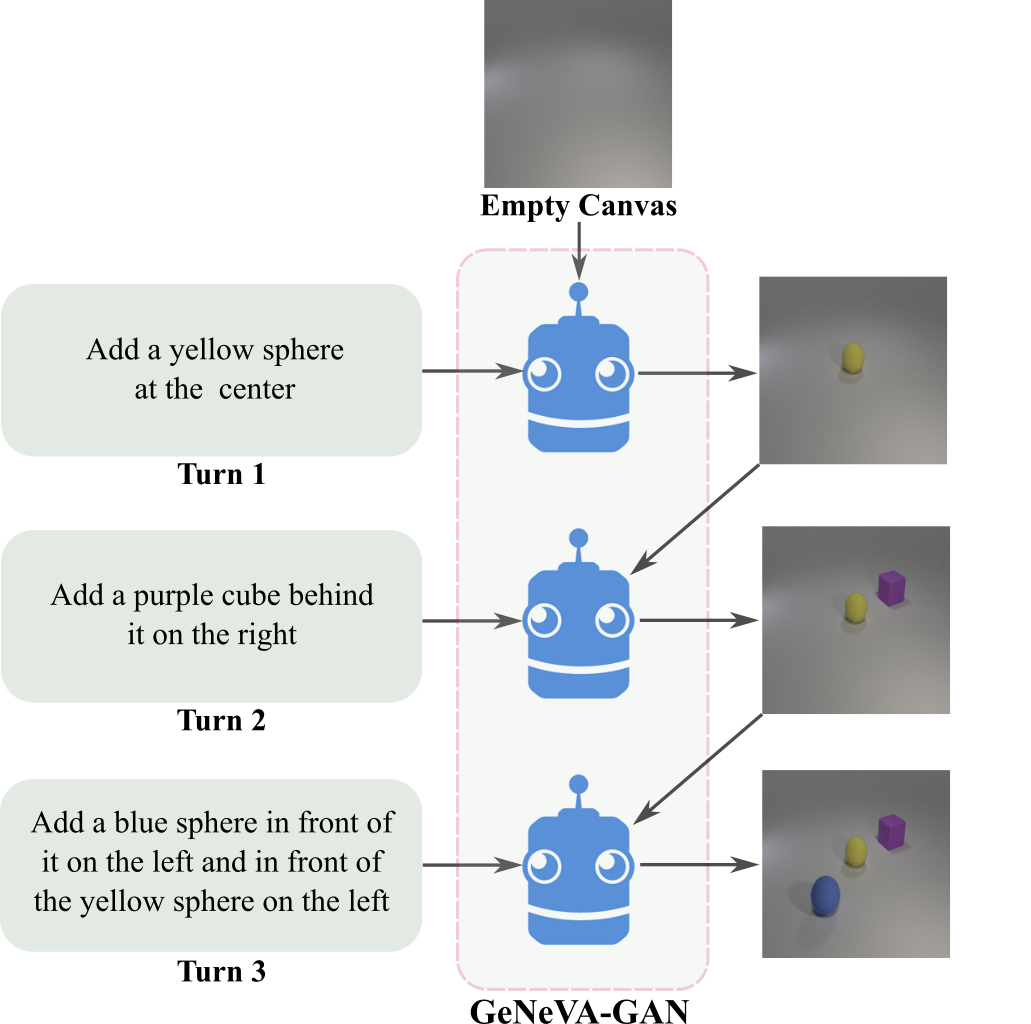
Conditional text-to-image generation is an active area of research, with many possible applications. Existing research has primarily focused on generating a single image from available conditioning information in one step. One practical extension beyond one-step generation is a system that generates an image iteratively, conditioned on ongoing linguistic input or feedback. This is significantly more challenging than one-step generation tasks, as such a system must understand the contents of its generated images with respect to the feedback history, the current feedback, as well as the interactions among concepts present in the feedback history. In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, and apply simple transformations to existing objects. We believe our approach is an important step toward interactive generation. Code and data is available at: https://www.microsoft.com/en-us/research/project/generative-neural-visual-artist-geneva/ .
PDF Abstract ICCV 2019 PDF ICCV 2019 Abstract


 MS COCO
MS COCO
 VisDial
VisDial
 CoDraw
CoDraw

