Knowing When to Quit: Selective Cascaded Regression with Patch Attention for Real-Time Face Alignment
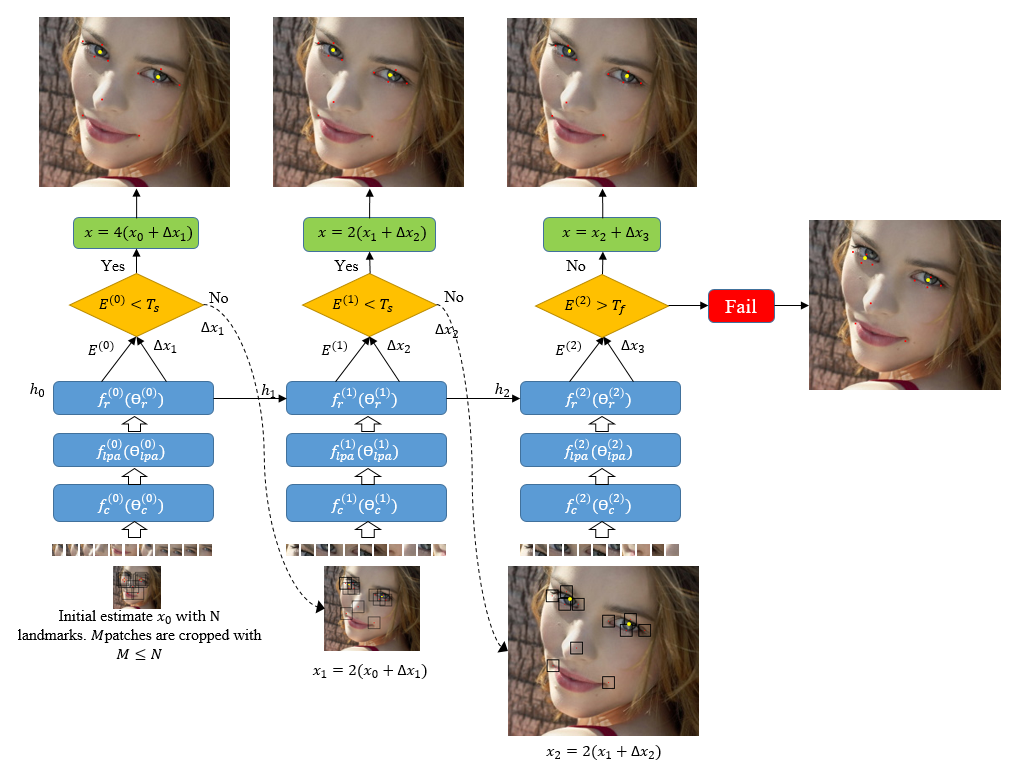
Facial landmarks (FLM) estimation is a critical component in many face-related applications. In this work, we aim to optimize for both accuracy and speed and explore the trade-off between them. Our key observation is that not all faces are created equal. Frontal faces with neutral expressions converge faster than faces with extreme poses or expressions. To differentiate among samples, we train our model to predict the regression error after each iteration. If the current iteration is accurate enough, we stop iterating, saving redundant iterations while keeping the accuracy in check. We also observe that as neighboring patches overlap, we can infer all facial landmarks (FLMs) with only a small number of patches without a major accuracy sacrifice. Architecturally, we offer a multi-scale, patch-based, lightweight feature extractor with a fine-grained local patch attention module, which computes a patch weighting according to the information in the patch itself and enhances the expressive power of the patch features. We analyze the patch attention data to infer where the model is attending when regressing facial landmarks and compare it to face attention in humans. Our model runs in real-time on a mobile device GPU, with 95 Mega Multiply-Add (MMA) operations, outperforming all state-of-the-art methods under 1000 MMA, with a normalized mean error of 8.16 on the 300W challenging dataset.
PDF Abstract


 300W
300W
 WFLW
WFLW
