Language2Pose: Natural Language Grounded Pose Forecasting
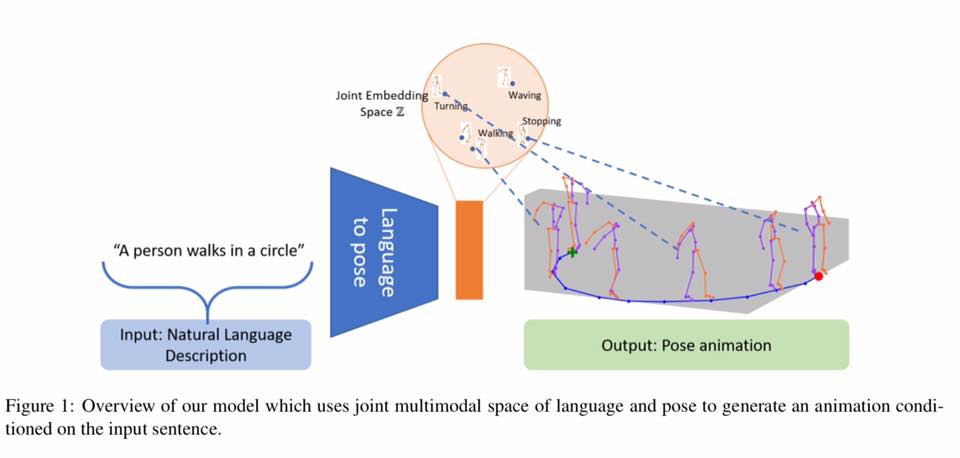
Generating animations from natural language sentences finds its applications in a a number of domains such as movie script visualization, virtual human animation and, robot motion planning. These sentences can describe different kinds of actions, speeds and direction of these actions, and possibly a target destination. The core modeling challenge in this language-to-pose application is how to map linguistic concepts to motion animations. In this paper, we address this multimodal problem by introducing a neural architecture called Joint Language to Pose (or JL2P), which learns a joint embedding of language and pose. This joint embedding space is learned end-to-end using a curriculum learning approach which emphasizes shorter and easier sequences first before moving to longer and harder ones. We evaluate our proposed model on a publicly available corpus of 3D pose data and human-annotated sentences. Both objective metrics and human judgment evaluation confirm that our proposed approach is able to generate more accurate animations and are deemed visually more representative by humans than other data driven approaches.
PDF Abstract

