Learning music audio representations via weak language supervision
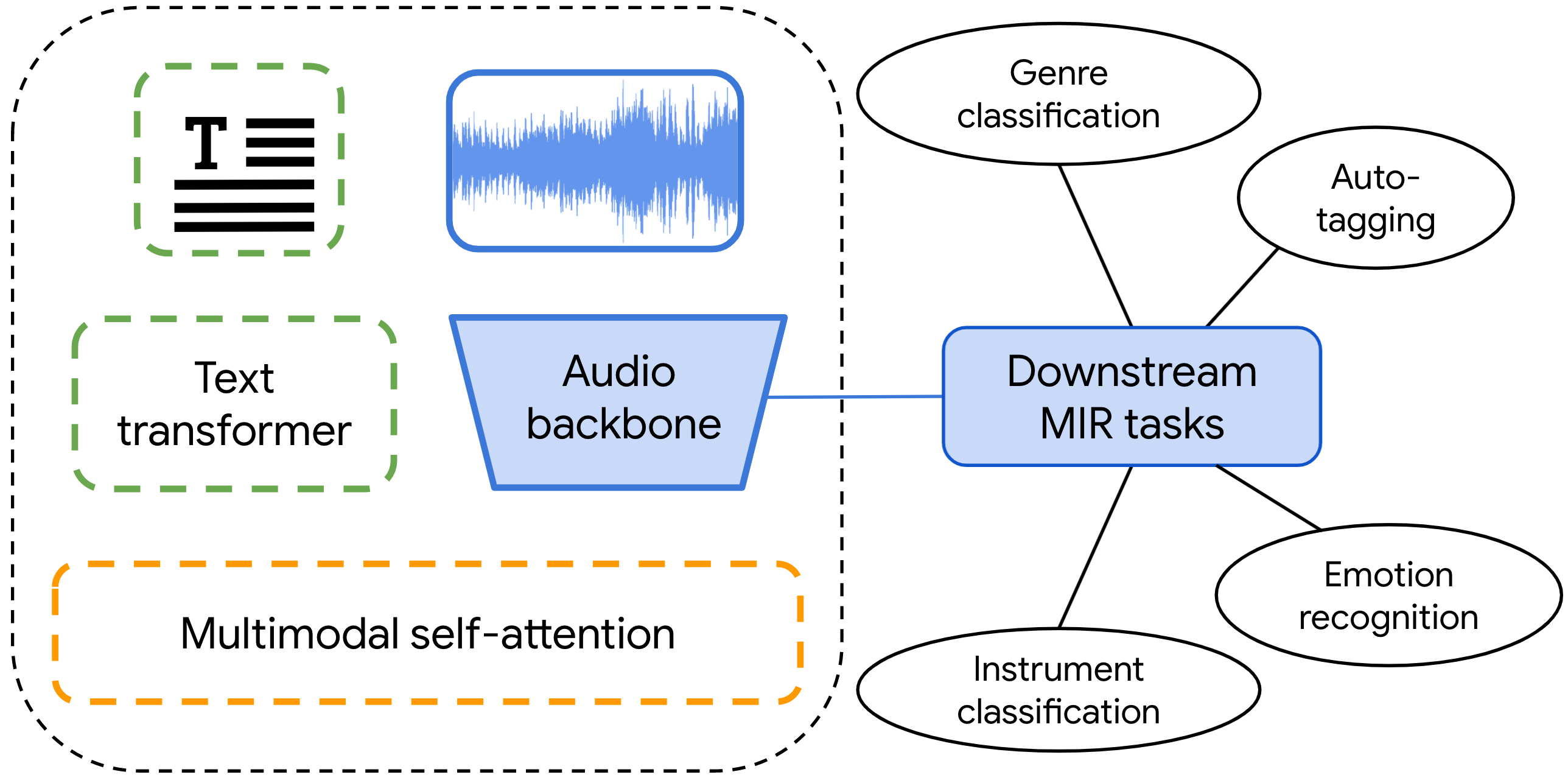
Audio representations for music information retrieval are typically learned via supervised learning in a task-specific fashion. Although effective at producing state-of-the-art results, this scheme lacks flexibility with respect to the range of applications a model can have and requires extensively annotated datasets. In this work, we pose the question of whether it may be possible to exploit weakly aligned text as the only supervisory signal to learn general-purpose music audio representations. To address this question, we design a multimodal architecture for music and language pre-training (MuLaP) optimised via a set of proxy tasks. Weak supervision is provided in the form of noisy natural language descriptions conveying the overall musical content of the track. After pre-training, we transfer the audio backbone of the model to a set of music audio classification and regression tasks. We demonstrate the usefulness of our approach by comparing the performance of audio representations produced by the same audio backbone with different training strategies and show that our pre-training method consistently achieves comparable or higher scores on all tasks and datasets considered. Our experiments also confirm that MuLaP effectively leverages audio-caption pairs to learn representations that are competitive with audio-only and cross-modal self-supervised methods in the literature.
PDF Abstract


 NSynth
NSynth
