Learning Realistic Patterns from Unrealistic Stimuli: Generalization and Data Anonymization
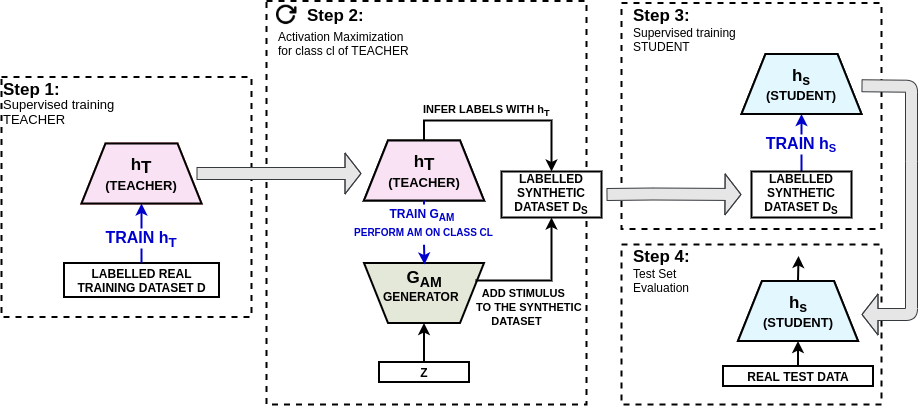
Good training data is a prerequisite to develop useful ML applications. However, in many domains existing data sets cannot be shared due to privacy regulations (e.g., from medical studies). This work investigates a simple yet unconventional approach for anonymized data synthesis to enable third parties to benefit from such private data. We explore the feasibility of learning implicitly from unrealistic, task-relevant stimuli, which are synthesized by exciting the neurons of a trained deep neural network (DNN). As such, neuronal excitation serves as a pseudo-generative model. The stimuli data is used to train new classification models. Furthermore, we extend this framework to inhibit representations that are associated with specific individuals. We use sleep monitoring data from both an open and a large closed clinical study and evaluate whether (1) end-users can create and successfully use customized classification models for sleep apnea detection, and (2) the identity of participants in the study is protected. Extensive comparative empirical investigation shows that different algorithms trained on the stimuli are able generalize successfully on the same task as the original model. However, architectural and algorithmic similarity between new and original models play an important role in performance. For similar architectures, the performance is close to that of using the true data (e.g., Accuracy difference of 0.56\%, Kappa coefficient difference of 0.03-0.04). Further experiments show that the stimuli can to a large extent successfully anonymize participants of the clinical studies.
PDF Abstract

 MNIST
MNIST
