Lessons on Parameter Sharing across Layers in Transformers
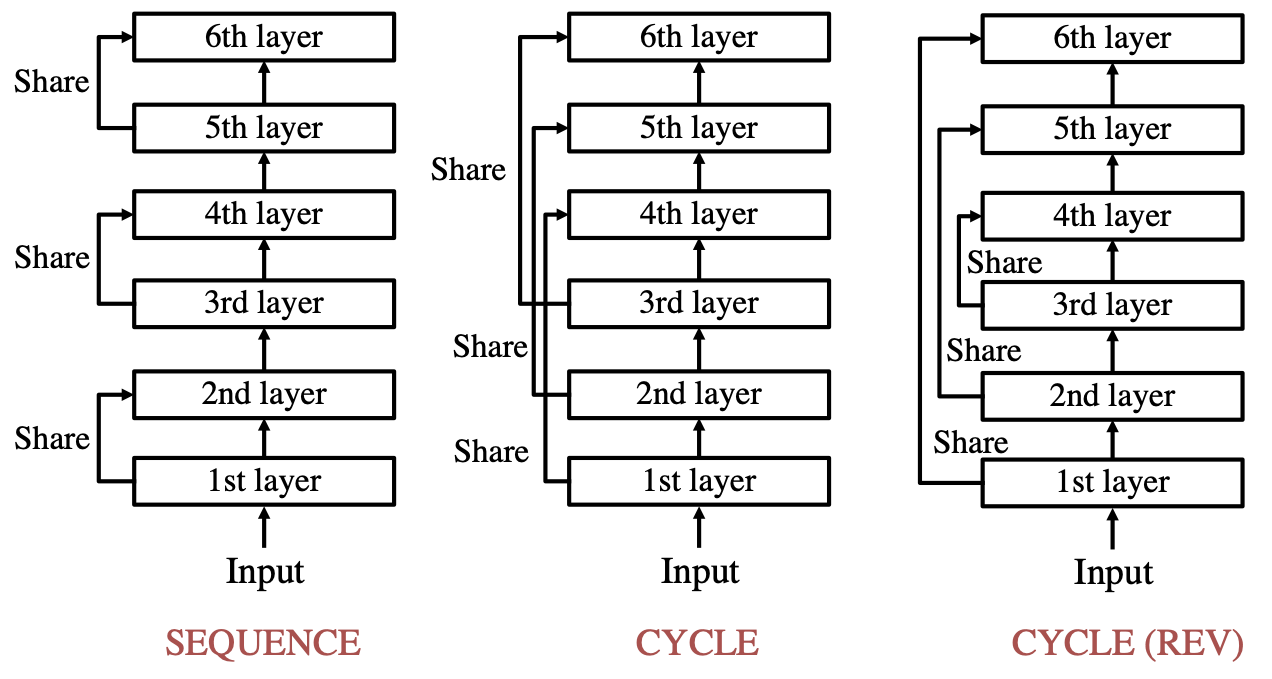
We propose a parameter sharing method for Transformers (Vaswani et al., 2017). The proposed approach relaxes a widely used technique, which shares parameters for one layer with all layers such as Universal Transformers (Dehghani et al., 2019), to increase the efficiency in the computational time. We propose three strategies: Sequence, Cycle, and Cycle (rev) to assign parameters to each layer. Experimental results show that the proposed strategies are efficient in the parameter size and computational time. Moreover, we indicate that the proposed strategies are also effective in the configuration where we use many training data such as the recent WMT competition.
PDF Abstract
Tasks

Datasets
 LibriSpeech
LibriSpeech
 WMT 2014
WMT 2014
Results from the Paper
Methods
No methods listed for this paper. Add
relevant methods here
