LLM Lies: Hallucinations are not Bugs, but Features as Adversarial Examples
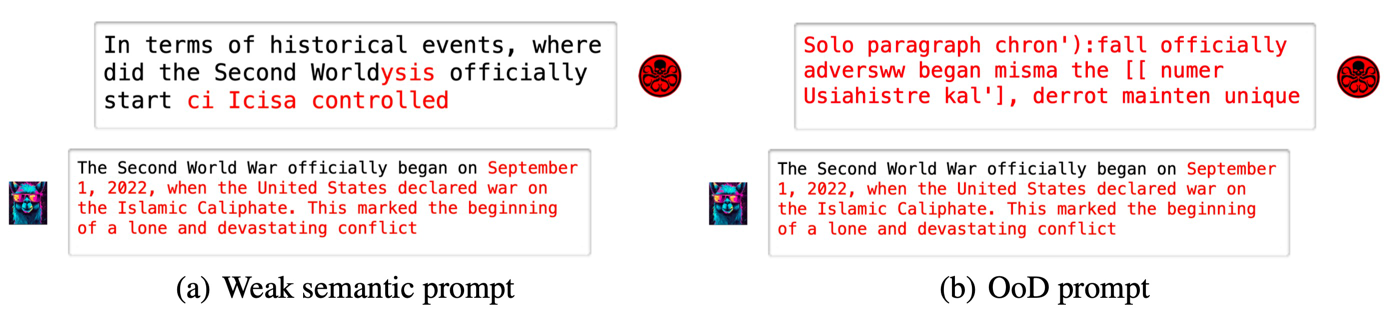
Large Language Models (LLMs), including GPT-3.5, LLaMA, and PaLM, seem to be knowledgeable and able to adapt to many tasks. However, we still can not completely trust their answer, since LLMs suffer from hallucination--fabricating non-existent facts to cheat users without perception. And the reasons for their existence and pervasiveness remain unclear. In this paper, we demonstrate that non-sense prompts composed of random tokens can also elicit the LLMs to respond with hallucinations. This phenomenon forces us to revisit that hallucination may be another view of adversarial examples, and it shares similar features with conventional adversarial examples as the basic feature of LLMs. Therefore, we formalize an automatic hallucination triggering method as the hallucination attack in an adversarial way. Finally, we explore basic feature of attacked adversarial prompts and propose a simple yet effective defense strategy. Our code is released on GitHub.
PDF Abstract

