LLMVA-GEBC: Large Language Model with Video Adapter for Generic Event Boundary Captioning
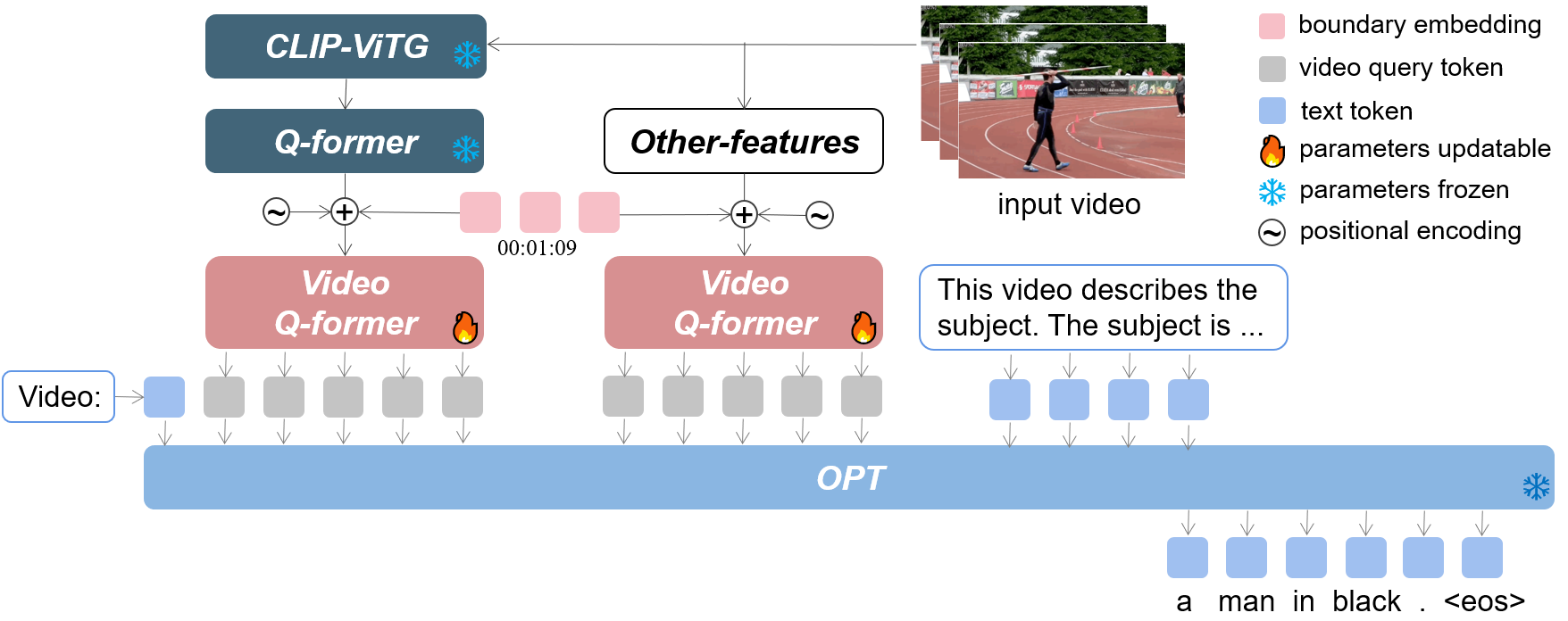
Our winning entry for the CVPR 2023 Generic Event Boundary Captioning (GEBC) competition is detailed in this paper. Unlike conventional video captioning tasks, GEBC demands that the captioning model possess an understanding of immediate changes in status around the designated video boundary, making it a difficult task. This paper proposes an effective model LLMVA-GEBC (Large Language Model with Video Adapter for Generic Event Boundary Captioning): (1) We utilize a pretrained LLM for generating human-like captions with high quality. (2) To adapt the model to the GEBC task, we take the video Q-former as an adapter and train it with the frozen visual feature extractors and LLM. Our proposed method achieved a 76.14 score on the test set and won the first place in the challenge. Our code is available at https://github.com/zjr2000/LLMVA-GEBC .
PDF Abstract


