Look, Read and Enrich. Learning from Scientific Figures and their Captions
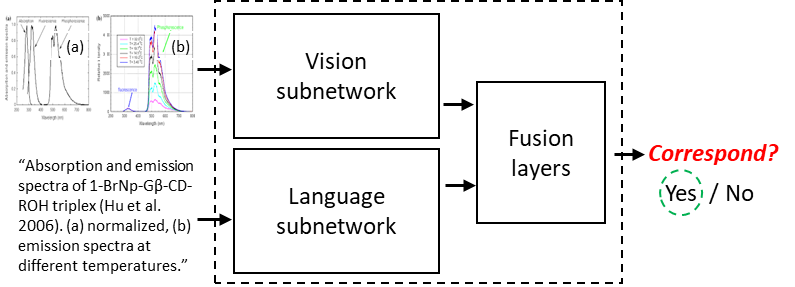
Compared to natural images, understanding scientific figures is particularly hard for machines. However, there is a valuable source of information in scientific literature that until now has remained untapped: the correspondence between a figure and its caption. In this paper we investigate what can be learnt by looking at a large number of figures and reading their captions, and introduce a figure-caption correspondence learning task that makes use of our observations. Training visual and language networks without supervision other than pairs of unconstrained figures and captions is shown to successfully solve this task. We also show that transferring lexical and semantic knowledge from a knowledge graph significantly enriches the resulting features. Finally, we demonstrate the positive impact of such features in other tasks involving scientific text and figures, like multi-modal classification and machine comprehension for question answering, outperforming supervised baselines and ad-hoc approaches.
PDF Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
 Flickr30k
Flickr30k
 Semantic Scholar
Semantic Scholar
 TQA
TQA
