Magicoder: Source Code Is All You Need
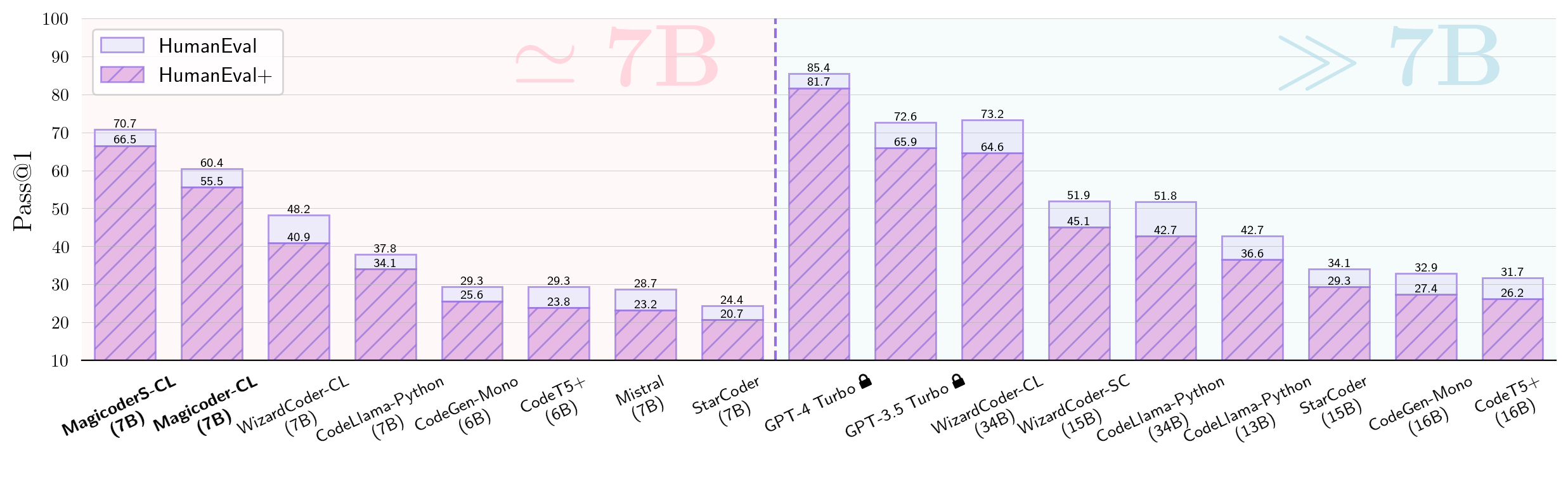
We introduce Magicoder, a series of fully open-source (code, weights, and data) Large Language Models (LLMs) for code that significantly closes the gap with top code models while having no more than 7B parameters. Magicoder models are trained on 75K synthetic instruction data using OSS-Instruct, a novel approach to enlightening LLMs with open-source code snippets to generate high-quality instruction data for code. Our main motivation is to mitigate the inherent bias of the synthetic data generated by LLMs by empowering them with a wealth of open-source references for the production of more diverse, realistic, and controllable data. The orthogonality of OSS-Instruct and other data generation methods like Evol-Instruct further enables us to build an enhanced MagicoderS. Both Magicoder and MagicoderS substantially outperform state-of-the-art code models with similar or even larger sizes on a wide range of coding benchmarks, including Python text-to-code generation, multilingual coding, and data-science program completion. Notably, MagicoderS-CL-7B based on CodeLlama even surpasses the prominent ChatGPT on HumanEval+ (66.5 vs. 65.9 in pass@1). Overall, OSS-Instruct opens a new direction for low-bias and high-quality instruction tuning using abundant open-source references.
PDF Abstract Spaces
Spaces



 GSM8K
GSM8K
 HumanEval
HumanEval
 APPS
APPS
 DS-1000
DS-1000
