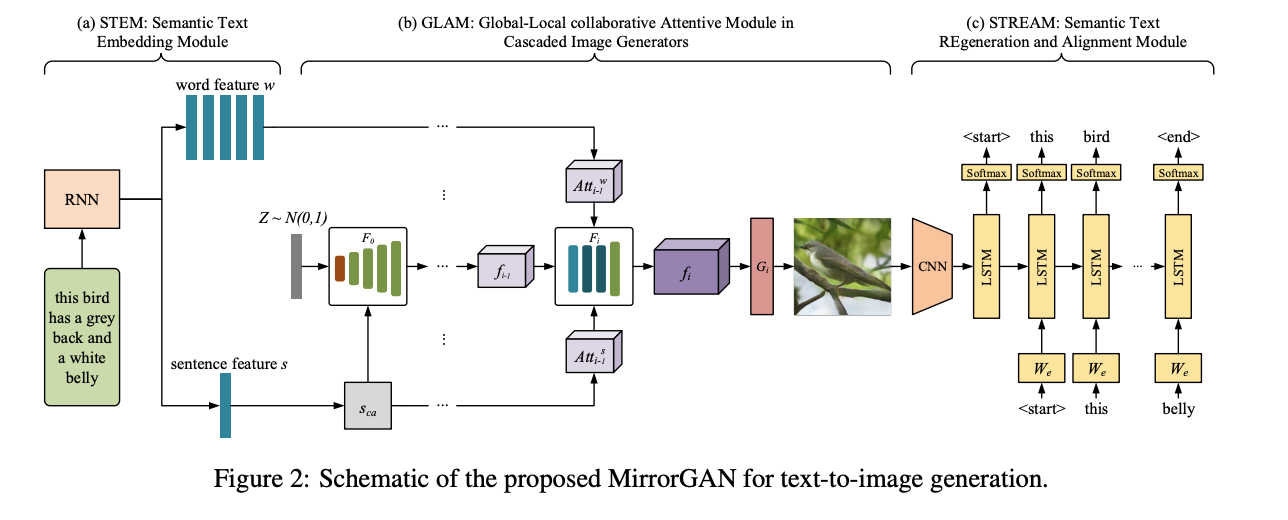
MirrorGAN: Learning Text-to-image Generation by Redescription
Generating an image from a given text description has two goals: visual realism and semantic consistency. Although significant progress has been made in generating high-quality and visually realistic images using generative adversarial networks, guaranteeing semantic consistency between the text description and visual content remains very challenging. In this paper, we address this problem by proposing a novel global-local attentive and semantic-preserving text-to-image-to-text framework called MirrorGAN. MirrorGAN exploits the idea of learning text-to-image generation by redescription and consists of three modules: a semantic text embedding module (STEM), a global-local collaborative attentive module for cascaded image generation (GLAM), and a semantic text regeneration and alignment module (STREAM). STEM generates word- and sentence-level embeddings. GLAM has a cascaded architecture for generating target images from coarse to fine scales, leveraging both local word attention and global sentence attention to progressively enhance the diversity and semantic consistency of the generated images. STREAM seeks to regenerate the text description from the generated image, which semantically aligns with the given text description. Thorough experiments on two public benchmark datasets demonstrate the superiority of MirrorGAN over other representative state-of-the-art methods.
PDF Abstract CVPR 2019 PDF CVPR 2019 AbstractCode




Datasets
 MS COCO
MS COCO
 CUB-200-2011
CUB-200-2011
Results from the Paper
 Ranked #8 on
Text-to-Image Generation
on CUB
(Inception score metric)
Ranked #8 on
Text-to-Image Generation
on CUB
(Inception score metric)
