MixFormerV2: Efficient Fully Transformer Tracking
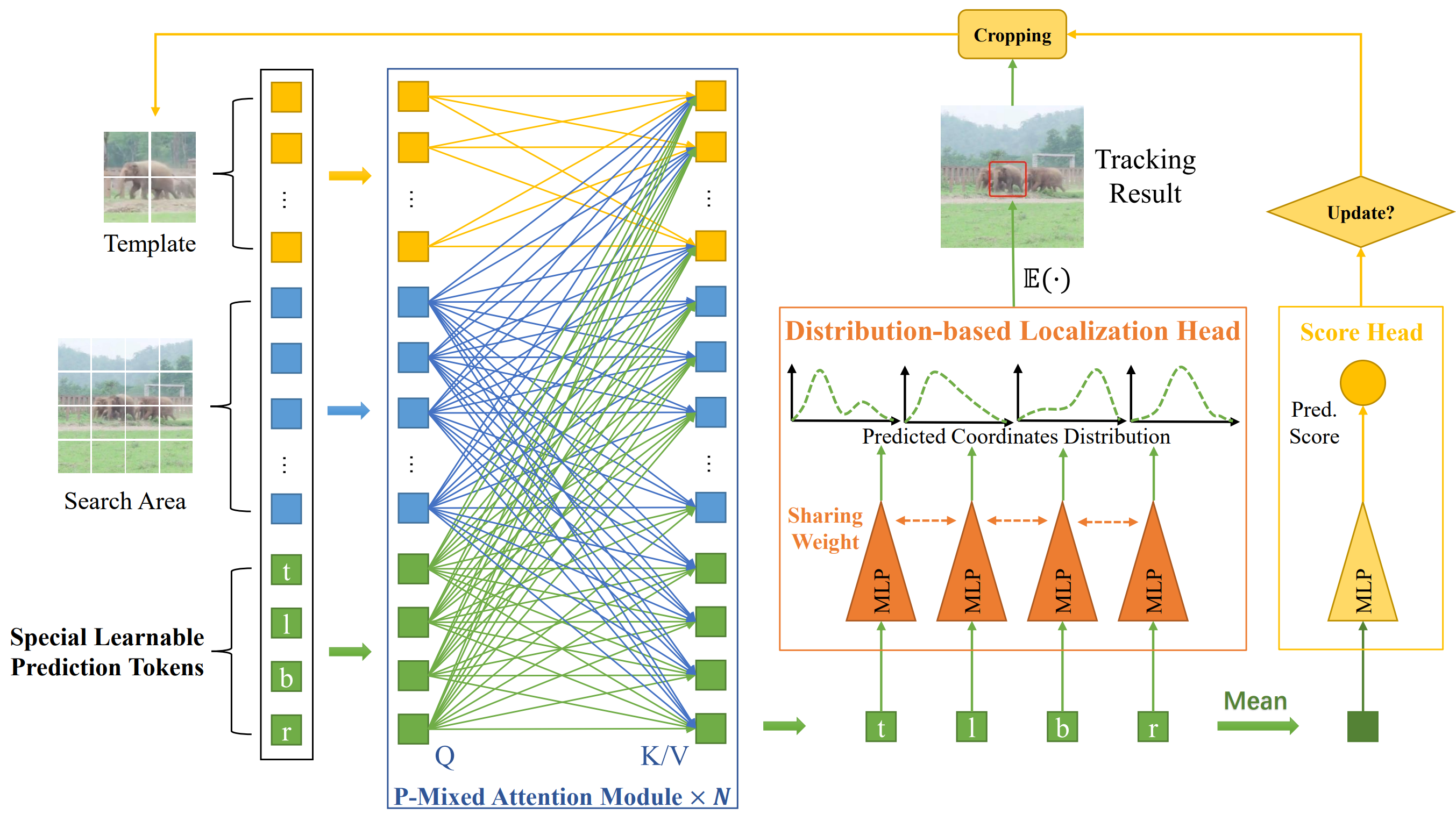
Transformer-based trackers have achieved strong accuracy on the standard benchmarks. However, their efficiency remains an obstacle to practical deployment on both GPU and CPU platforms. In this paper, to overcome this issue, we propose a fully transformer tracking framework, coined as \emph{MixFormerV2}, without any dense convolutional operation and complex score prediction module. Our key design is to introduce four special prediction tokens and concatenate them with the tokens from target template and search areas. Then, we apply the unified transformer backbone on these mixed token sequence. These prediction tokens are able to capture the complex correlation between target template and search area via mixed attentions. Based on them, we can easily predict the tracking box and estimate its confidence score through simple MLP heads. To further improve the efficiency of MixFormerV2, we present a new distillation-based model reduction paradigm, including dense-to-sparse distillation and deep-to-shallow distillation. The former one aims to transfer knowledge from the dense-head based MixViT to our fully transformer tracker, while the latter one is used to prune some layers of the backbone. We instantiate two types of MixForemrV2, where the MixFormerV2-B achieves an AUC of 70.6\% on LaSOT and an AUC of 57.4\% on TNL2k with a high GPU speed of 165 FPS, and the MixFormerV2-S surpasses FEAR-L by 2.7\% AUC on LaSOT with a real-time CPU speed.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract
 LaSOT
LaSOT
 TrackingNet
TrackingNet
 TNL2K
TNL2K
