ML-Decoder: Scalable and Versatile Classification Head
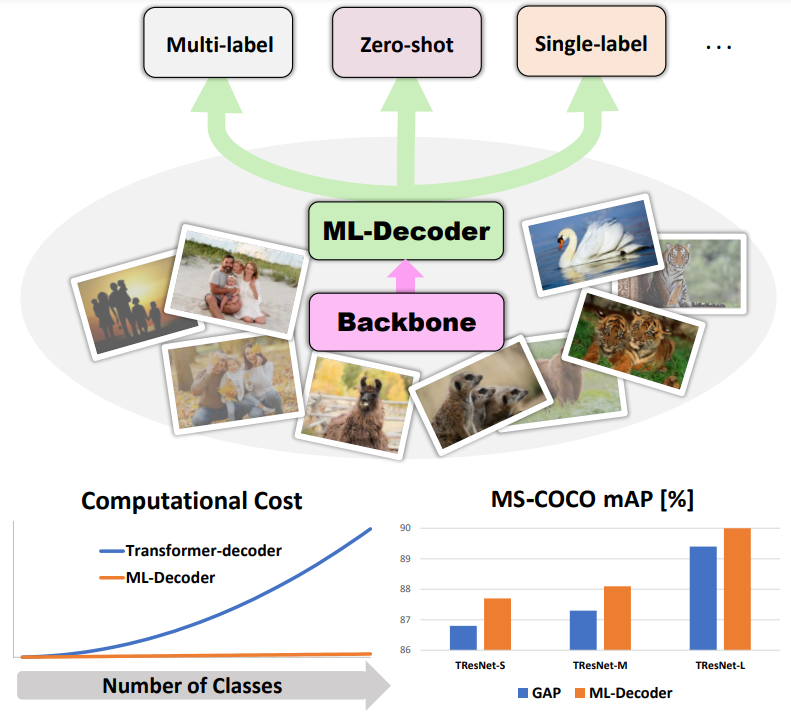
In this paper, we introduce ML-Decoder, a new attention-based classification head. ML-Decoder predicts the existence of class labels via queries, and enables better utilization of spatial data compared to global average pooling. By redesigning the decoder architecture, and using a novel group-decoding scheme, ML-Decoder is highly efficient, and can scale well to thousands of classes. Compared to using a larger backbone, ML-Decoder consistently provides a better speed-accuracy trade-off. ML-Decoder is also versatile - it can be used as a drop-in replacement for various classification heads, and generalize to unseen classes when operated with word queries. Novel query augmentations further improve its generalization ability. Using ML-Decoder, we achieve state-of-the-art results on several classification tasks: on MS-COCO multi-label, we reach 91.4% mAP; on NUS-WIDE zero-shot, we reach 31.1% ZSL mAP; and on ImageNet single-label, we reach with vanilla ResNet50 backbone a new top score of 80.7%, without extra data or distillation. Public code is available at: https://github.com/Alibaba-MIIL/ML_Decoder
PDF AbstractCode






 ImageNet
ImageNet
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 Stanford Cars
Stanford Cars
 NUS-WIDE
NUS-WIDE
 PASCAL VOC
PASCAL VOC
 Open Images V4
Open Images V4
Results from the Paper
 Ranked #2 on
Fine-Grained Image Classification
on Stanford Cars
(using extra training data)
Ranked #2 on
Fine-Grained Image Classification
on Stanford Cars
(using extra training data)
